

CSV in Python importieren mit Pandas
Das am weitesten verbreitete Dateiformat für tabellarische Daten ist und bleibt das CSV-Format. Hier lernst du, wie du CSV-Dateien sicher in deine Programmierumgebung einliest.
Was sind CSV-Dateien?
Die Abkürzung CSV steht für „Comma Separated Values“ – CSV’s sind also Dateien, die durch Kommata getrennte Werte enthalten. Durch ihr einfach zu interpretierendes Format ist diese Dateiform mit den allermeisten Technologien kompatibel und wird genutzt, um Rohdaten abzuspeichern.
CSV ist nicht gleich CSV
Obwohl alle kommaseparierten Dateien dieselbe Endung besitzen, heißt das nicht, dass sie alle gleich formatiert sind. Ein Beispiel ist das Komma, welches bei Computern zu großer Verwirrung führen kann. Zum einen wird dieses Zeichen standardmäßig als Trennzeichen innerhalb der Datei benutzt. Gleichzeitig findet es im deutschsprachigen Raum Anwendung bei der Darstellung von Dezimalzahlen. Da kann Python schon mal durcheinander kommen. Was es noch für andere Stolperfallen gibt, findest du später heraus.
Was du für das Tutorial brauchst
Du kannst das Tutorial natürlich einfach lesen und nachvollziehen oder die Tipps an eigenen Daten ausprobieren.
Falls du die Anleitung genau so nachmachen willst, brauchst du 3 Dinge.
- Python.
- Numpy: Steht für „Numerical Python“ und ist eine Bibliothek für die effiziente Rechnung mit Arrays und Matrizen.
- Pandas: Basiert auf Numpy auf und ist das meistgenutzte Package für die Verarbeitung tabellarischer Daten.
Je nach Python-Distribution (Anaconda ist sehr beliebt bei Data Scientists) sind Numpy und Pandas schon im Paket enthalten.
Als Übungsdatei kannst du dir die unten stehende CSV-Datei herunterladen.
Datei „Auto.csv“ herunterladen
Diese enthält 20 auf einer Online-Plattform zum Verkauf angebotene Autos mit ihren wichtigsten Eigenschaften.
Package importieren
Nachdem du die Datei heruntergeladen hast, kannst du Python starten und Pandas wie folgt importieren.
import pandas as pd
Numpy bildet zwar die Basis für Pandas, muss aber nicht direkt in die Programmierumgebung importiert werden.
Die Funktion, um die sich hier alles dreht, heißt .read_csv(). Diese werden wir im folgenden auseinandernehmen.
Datei importieren
Und so wendest du die Funktion an.
df = pd.read_csv("...DeinPfad/Auto.csv")
Das einzige notwendige Argument der Funktion ist der Pfad der Datei, die importiert werden soll. Schauen wir sie uns mal in Python an.
df

Das hat so nicht hingehauen. Pandas geht davon aus, dass wir eine Datei einlesen, in der die Werte auch wirklich durch Kommata getrennt sind. Das ist hier nicht der Fall und passiert zum Beispiel, wenn man eine Excel-Datei als CSV abspeichert. Der Separator in unserer Datei ist ein Semikolon und wird nicht erkannt. Deshalb definieren wir innerhalb der Funktion explizit das Semikolon als Trennungszeichen.
df = pd.read_csv("...DeinPfad/Auto.csv",sep=";")
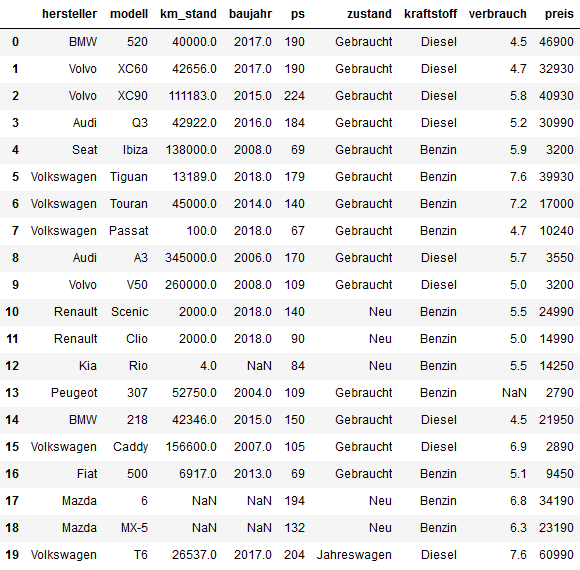
Jetzt sieht der DataFrame so aus:

Das sieht doch nach einem korrekt eingelesenen DataFrame aus. Alle leeren Einträge werden übrigens automatisch mit NaN (not a number) befüllt. Was jetzt nicht gleich auffällt, aber später hinderlich wird, sind die Kommata in der Spalte Verbrauch. Diese sind eigentlich zur Darstellung von Dezimalzahlen gedacht, Pandas erkennt sie jedoch nicht als diese. Also wird die Spalte im Moment als Text behandelt.
Das Problem lösen wir, indem wir beim Import nicht nur das Trennungszeichen, sondern auch das Dezimalzeichen explizit angeben.
df = pd.read_csv("...DeinPfad/Auto.csv",sep=";",decimal=",")
Das Ergebnis ist folgendes:

Pandas hat die Kommata in Punkte umgewandelt, womit wir die Spalte nun auch für Berechnungen nutzen können
Spaltennamen beim Import ändern
Ein weiteres Feature der Funktion ist es, dass du beim Import direkt die Spalten umbenennen kann. Das Ganze funktioniert mit dem Argument names. Falls du beim Import neue Namen vergeben willst, musst du gleichzeitig mit dem Argument header angeben, in welcher Zeile sich die ursprünglichen Spaltennamen befinden. Sonst denkt Pandas, dass es noch gar keine Namen gibt und behandelt die Kopfzeile wie ganz normalen Spalteneinträge. Richtig machst du es also so:
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
header=0,
names=["hersteller",
"modell",
"km_stand",
"baujahr",
"ps",
"zustand",
"kraftstoff",
"verbrauch",
"preis"])
Der Befehl ist auch praktisch für Situationen, in denen du CSV-Dateien ohne Spaltenüberschriften hast. In diesem Fall weist du dem Argument header den Wert None zu, und zwar so:
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
header=None,
names=["hersteller",
"modell",
"km_stand",
"baujahr",
"ps",
"zustand",
"kraftstoff",
"verbrauch",
"preis"])

Wir haben hier natürlich Überschriften, deshalb macht es für uns keinen Sinn. Es gibt jedoch Situationen, in denen der Befehl sehr nützlich sein kann.
Spalten beim Import auswählen
Manchmal willst du gar keine komplette Tabelle importieren, sondern nur bestimmte Spalten. Dies kann u.a. folgende Gründe haben.
- Dich interessiert nur eine Teilmenge der Spalten.
- Du willst eine bessere Übersicht über deinen Datensatz haben.
- Deine Ressourcen sind begrenzt, du willst schneller mit den vorhandenen Daten arbeiten.
Auch für diese Aufgabe bietet Pandas eine passende Lösung, und zwar mit dem Argument usecols.
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
usecols=["Hersteller","Modell","Preis"])

Wie du siehst hat Pandas nur die explizit genannten Spalten importiert. Das kann eine Datenanalyse schneller und übersichtlicher machen.
Zeilen beim Import auswählen
Auch für die händische Selektierung von Zeilen bietet Pandas einiges an Möglichkeiten. Zum Beispiel kannst du mit skiprows Zeilen nennen, die nicht in deine Programmierumgebung eingelesen werden sollen.
Zeile(n) am Anfang überspringen:
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
skiprows=3,
names = ["hersteller",
"modell",
"kilometerstand",
"baujahr",
"ps",
"zustand",
"kraftstoff",
"verbrauch",
"preis"])
Hier haben wir Pandas gesagt, dass beim Import die ersten 3 Zeilen übersprungen werden sollen. Doch Achtung! Die Kopfzeile mit den Überschriften wird mit übersprungen, sodass diese und die beiden ersten Zeilen mit Daten nicht importiert werden. Deshalb vergeben wir im obigen Befehl explizit Spaltennamen. Das Ergebnis sieht dann so aus:

Zeile(n) am Ende überspringen:
Dasselbe wie oben kannst du auch mit dem unteren Ende der Tabelle tun. Das passende Argument innerhalb er Funktion heißt skipfooter.
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
skipfooter=3)
Analog zu oben haben wir Pandas jetzt gesagt, dass die letzten 3 Zeilen weggelassen werden sollen.

Bestimme Anzahl von Zeilen importieren:
Zusätzlich zu den beiden Optionen oben kannst du mit dem Argument nrows angeben, wie viele Zeilen insgesamt importiert werden sollen.
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
nrows=10)
Im Gegensatz zu skiprows erkennt Pandas hier automatisch die Spaltenüberschriften und importiert diese zusammen mit den angegebenen 10 Zeilen mit Daten.

Index selbst definieren
In den Beispielen oben siehst du, dass Pandas jedes Mal der Tabelle einen eindeutigen Zeilenindex verpasst hat. Allerdings kannst du diesen beim Import direkt definieren. Zum Beispiel kannst du mit dem Argument index_col eine oder mehrere Spalten als Index verwenden.
Eine Spalte als Index verwenden:
Wenn du nur eine Spalte als Index setzen willst, kannst du ihren Namen einfach als String dem Argument übergeben.
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
index_col="Hersteller")

Wie du siehst hat Pandas die Spalte Hersteller zum Index gemacht. Dieser Index ist jedoch nicht eindeutig, manche Einträge wiederholen sich. Du kannst jedoch auch mehrere Spalten nutzen, um aus ihnen einen Multiindex zu machen.
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
index_col=["Hersteller","Modell"])
df.sort_index()

Jetzt haben wir mit den Spalten Hersteller und Modell (dieses Mal als Liste von Strings) einen Multiindex erstellt, mit dessen Hilfe sich die Zeilen des DataFrames eindeutig ansprechen lassen. Mit dem Befehl .sort_index() wird die Tabelle nach dem Index sortiert dargestellt.
Wahrheitswerte vorgeben
Standardmäßig verwendet Python True und False als Wahrheitswerte. Oft ist es jedoch der Fall, dass in Rohdaten andere Werte – zum Beispiel Ja und Nein – als Wahrheitswerte genutzt wurden. Simulieren wir diesen Fall einmal, indem wir in der Übungsdatei eine Hilfspalte namens Gebraucht hinzufügen, in welcher alle Gebrauchtwagen mit Ja und Neuwagen mit Nein gekennzeichnet werden. Die Datei speichern wir als Auto_Gebraucht.csv ab und importieren sie wie gewohnt.
df = pd.read_csv("...DeinPfad/Auto_Gebraucht.csv",
sep=";",
decimal=",")

Rechts siehst du die relevante Spalte. Sie enthält wertvolle Informationen, lässt sich so allerdings nur bedingt für weitere Analyen nutzen. Deshalb kannst du mit den Argumenten true_values und false_values dafür sorgen, dass Ja und Nein gleich beim Import in True und False umgewandelt werden.
df = pd.read_csv("...DeinPfad/Auto_Gebraucht.csv",
sep=";",
decimal=",",
true_values=["Ja"],
false_values=["Nein"])
An den eckigen Klammern kannst du erkennen, dass du die Wahrheitswerte jeweils als Liste übergibst. Das bedeutet gleichzeitig, dass du mehrere unterschiedliche Einträge als Wahrheitswerte übergeben kannst, welche Pandas dann alle erkennt. Das Ergebnis ist folgendes:

Umlaute richtig importieren
Ein häufig auftretendes Problem beim Importieren von Daten ist der Umgang von Pandas/Python mit Umlauten. Um dies zu erläutern, habe ich der vorhandenen Tabelle eine Zeile hinzugefügt, die einen Citroën beinhaltet. Sehen wir uns an, was üblicherweise mit Tabellen geschieht, in denen es Einträge mit Umlauten gibt.
df = pd.read_csv("...DeinPfad/Auto_Umlaute.csv",
sep=";",
decimal=",")
![]()
Und genau das passiert immer, wenn du versuchst, Umlaute oder andere Zeichen zu importieren, welche der Standard-Decoder nicht entziffern kann. Abhilfe schafft das Argument encoding, welchem du den Wert latin1 (Wikipedia) zuweist. So erkennt Pandas auch automatisch die Zeichen, die typisch für den westeuropäischen Raum sind.
df = pd.read_csv("...DeinPfad/Auto_Umlaute.csv",
sep=";",
decimal=",",
encoding="latin1")
Jetzt importiert Pandas die Daten korrekt. Der DataFrame sieht dann so aus:

Datentypen manuell zuweisen
Normalerweise „errät“ Pandas, aus welchen Datentypen die jeweiligen Spalten einer Tabelle bestehen, und weist diese automatisch zu. Bei großen Datenmengen kann dieses Vorgehen den Import bedeutend verlangsamen. Deshalb kannst du mit dem Argument dtype die Datentypen explizit zuweisen. Übergib dem genannten Argument einfach ein Dictionary, bestehend aus den Spaltennamen und den Datentypen, welche du vergeben möchtest.
df = pd.read_csv("...DeinPfad/Auto.csv",
sep=";",
decimal=",",
dtype={"Hersteller":str,
"Modell":str,
"Kilometerstand":float,
"Baujahr":float,
"PS":int,
"Zustand":str,
"Kraftstoff":str,
"Verbrauch":float,
"Preis":int})
Fazit
Das waren die wichtigsten Optionen, mit deren Hilfe du CSV-Dateien in deine Programmierumgebung einlesen kannst. In der Dokumention von Pandas findest du noch weitere Möglichkeiten, welche dir den Datenimport erleichtern. Außerdem erfährst du im Tutorial zur Gruppierung von Daten, wie du mit Pandas große Tabellen aggregieren und somit aussagekräftige Statistiken erstellen kannst. Wenn du alles über den Umgang mit und die Analyse von Daten in Python wissen willst, empfehle ich dir das unten stehende Buch von Wes McKinney – erschienen im O’Reilly Verlag.
Anzeige

In diesem Buch erfährst du auf über 400 Seiten, wie du…
- Daten einliest, bearbeitest und deskriptive Statistiken erstellst
- effizient mit ein- und mehrdimensionalen Arrays rechnest
- Daten visualisierst
- mit HTML-Code und Web-APIs interagierst, um selbst Daten zu minen
- Zeitreihen analysierst
…und vieles mehr. Die Technologien, welche du meistern wirst, umfassen Numpy, Pandas, Matplotlib und andere nützliche Python-Packages.
Viel Spaß beim Analysieren! 🙂
Eine Tasse Kaffee?
In diese Seite fließt viel Zeit und Energie. In mich fließt deshalb viel Kaffee. Falls dir der Beitrag also geholfen hat, findest du vielleicht noch ein bisschen Kleingeld zwischen deinen Sofakissen und möchtest mir einen Kaffee spendieren. 🙂
Wiedermal super Beitrag! Schon jetzt mein Lieblingsblog! Hoffe das noch zahlreiche weitere Beiträge folgen 😉
VG Daniel
Hi Daniel,
danke für dein Feedback. Es ist cool, zu sehen, dass die Beiträge anderen helfen! 🙂
Über welche Themen würdest du gern noch mehr wissen?
Viele Grüße
Chris
Moin,
Kann man den Auto Datensatz für eigene Übungen verwenden?
Hi Jasper,
klar, dafür ist er da.
Viele Grüße
Chris
Hallo Daniel,
im Text schreibst Du:
„In diesem Fall weist du dem Argument header den Wert None zu, und zwar so:“
Im Code dann steht dann „header=0“. Dies sollte jedoch „header=None“ heißen.
Beste Grüße
Jonas
Hi Jonas,
da hast du recht, gleich korrigiert. 🙂
Viele Grüße
Chris
Hallo Daniel,
mit ‚usecols‘ ist es möglich Spalten auszuwählen.
Ich habe eine Datei in der sich ca. 150 Spalten befinden. Von diesen 150 Spalten möchte ich die 1., 3. und 4. jedoch nicht einlesen. Du wirst mir zustimmen, dass der hier vorgeschlagene Weg etwas unhandlich ist. Meine Frage: Gibt es eine Möglichkeit ‚usecols‘ zu sagen, dass die 1., 3. und 4. ignoriert werden sollen?
Vielen Dank für Deine Bemühungen im Voraus.
Beste Grüße
Jonas
Gute Frage,
da musste ich gerade selbst überlegen. Du kannst z.B. mit einer List Comprehension arbeiten:
usecols=[i for i in range(150) if i not in [0,2,3]]Du kannst nämlich statt einer Namensliste auch eine Liste von Integer-Werten (0-indexiert) an das Argument
usecolsübergeben. Hier wird eine Liste mit Ganzzahlen von 0 bis 149 generiert, in der die Werte 0, 2 und 3 fehlen. Somit werde die 1.,3. und 4. Spalte nicht eingelesen.Ich hoffe, das hilft dir!
Viele Grüße
Chris
Hallo Chris,
es funktioniert. 🙂
Beste Grüße und ein schönes WE.
Jonas
Hallo Chris,
danke für den schönen und gut strukturierten Beitrag!
Frage: ich muss 100 csv-Files einlesen, bearbeiten und wenn sie nicht mehr brache schließen.
Wie kann ich die offene Datei mit Pandas wieder schließen? Ich finde nirgendswo einen Hinweis, ob man die geöffnete Datei wieder geschlossen sein muss. Wenn die Datei nicht geschlossen sein muss, wird nicht viel Speicherplatz verschwendet?
Viele Grüße
Louis
Wenn du deinen Handcash handle angibst, bekommst du einen Kaffee. Danke für deine Mühe!
vielen Dank 🙂
Super Scripte, die mir als Beginner sehr geholfen haben.
Eine Frage habe ich aber, und zwar, ist es möglich, den Index revers laufen zu lassen und alle anderen in der Tabelle vorhandenen Daten so zu belassen. Z.B. Index 0 wird zu 15? Wenn ja, wo muss ich ansetzen.
Vielen Dank
Markus
Hi Markus,
interessante Frage. Du kannst nach dem Einlesen den Index invertieren. Und zwar so:
df = df.reindex(index=reversed(df.index))
Hoffe, das hilft!
Viele Grüße
Chris