

Excel-Dateien in Python importieren mit Pandas
Hier erfährst du, wie du Excel-Dateien in Python importierst, um sie dann dort analysieren zu können.
Du willst Daten in Python analysieren. Doch dazu musst du erst mal an Daten kommen. Neben CSVs liegen Rohdaten auch oft als Excel-Dateien vor. Diese lassen sich fast genauso einfach wie CSV-Dateien in Python importieren (wie du das anstellst, habe ich übrigens im letzten Beitrag beschrieben).
Was du für das Tutorial brauchst
Wie im Tutrial für den CSV-Import brauchst kannst du auch hier entweder einfach nur mitlesen oder direkt selbst ausprobieren. Für letzteres brauchst du wieder drei Dinge.
Je nach Python-Distribution (Anaconda ist sehr beliebt bei Data Scientists) sind Numpy und Pandas schon im Paket enthalten.
Als Übungsdatei kannst du dir die unten stehende Exceldatei herunterladen.
Datei „Auto.xlsx“ herunterladen
Diese enthält 20 auf einer Online-Plattform zum Verkauf angebotene Autos mit ihren wichtigsten Eigenschaften.
Package importieren
Nachdem du die Datei heruntergeladen hast, kannst du Python starten und Pandas wie folgt importieren.
import pandas as pd
Numpy bildet zwar die Basis für Pandas, muss aber nicht direkt in die Programmierumgebung importiert werden.
Die Funktion, um die sich hier alles dreht, heißt .read_excel().
Datei importieren
Jetzt importieren wir die heruntergeladene Datei.
df = pd.read_excel("...DeinPfad/Auto.xlsx")
Mit dem Befehl wurde die Exceldatei als DataFrame namens df in deine Programmierumgebung geladen.
Das Ergebnis ist folgendes:

Die erste Zeile wird standardmäßig als Überschrift erkannt. Die Funktion .read_excel() macht außerdem einige Dinge, die von .read_csv() vernachlässigt werden, schon automatisch. Zum Beispiel wird das in der deutschen Excelversion verwendete Dezimalkomma direkt als solches erkannt. Auch hier werden leere Zellen wieder automatisch mit NaN (not a number) gefüllt.
Ein oder mehrere Tabellenblätter importieren
In der Dokumentation von Pandas findest du zu .read_excel() alle möglichen Argumente, mit denen du die Funktion noch ergänzen kannst. Sollte deine Exceldatei zum Beispiel mehrere Tabellenblätter enthalten, dann kannst du mit dem Argument sheet_name explizit die Blätter auswählen, die importiert werden sollen (Wenn du mit einer alten Pandas-Version arbeitest, kann es sein, dass du statt sheet_name als Argument sheetname eingeben musst). Zum Mitmachen kannst du dir hier die Exceldatei Auto2 herunterladen. Diese enthält zwei Tabellenblätter namens Auto und Haendler. Zuerst versuchen wir noch mal denselben Befehl wie oben.
df = pd.read_excel("...DeinPfad/Auto2.xlsx")
Das Ergebnis ist dasselbe wie oben. Wenn du innerhalb der Funktion kein Tabellenblatt angibst, wird automatisch das erste Blatt importiert. Um nur das zweite Blatt zu importieren, machst du folgendes:
df = pd.read_excel("...DeinPfad/Auto2.xlsx",sheet_name=1)

Alternativ kannst du dem Argument auch den in der Datei sichtbaren Namen Haendler zuweisen, das Ergebnis bleibt dasselbe. Mehrere Blätter gleichzeitig importierst du, indem du dem Argument eine Liste zuweist. Diese kann aus Nummern oder den sichtbaren Namen bestehen. Darum importieren die folgenden Befehle allesamt die komplette Exceldatei in Python.
df = pd.read_excel("...DeinPfad/Auto2.xlsx",sheet_name=[0,1])
df = pd.read_excel("...DeinPfad/Auto2.xlsx",sheet_name=["Auto", "Haendler"])
df = pd.read_excel("...DeinPfad/Auto2.xlsx",sheet_name=["Auto", 1])
Das Objekt df ist jetzt allerdings kein DataFrame mehr, sondern ein Python-Dictionary, in dem sich für jedes Tabellenblatt der Name als Schlüssel und der dazugehörige DataFrame als Wert befindet. Der Name entspricht dem, was du dem Argument sheet_name zugewiesen hast. Der dritte Befehl oben liefert folgendes Ergebnis:

Der Befehl…
df["Haendler"]
…liefert dementsprechend wieder einen DataFrame.
Spaltennamen ändern
Willst du beim Import andere Spaltennamen definieren? Kein Problem mit dem Argument names. Weise dem Argument einfach eine Liste mit Namen zu, welche du vergeben willst.
df = pd.read_excel("...DeinPfad/Auto.xlsx",
names=["a","b","c","d","e","f","g","h","i"])
df.head()

Dieses Argument kann vor allem dann nützlich sein, wenn deine Datei von sich aus gar keine Spaltennamen besitzt. Um einer solchen Datei beim Import neue Namen zu geben, musst du in der Funktion allerdings angeben, dass es keine Überschriften gibt. Das tust du mit dem Argument header. Tun wir mal so, als wäre die erste Zeile keine Überschrift, sondern würde mit zu den Werten gehören.
df = pd.read_excel("...DeinPfad/Auto.xlsx",
header=None)
df.head()

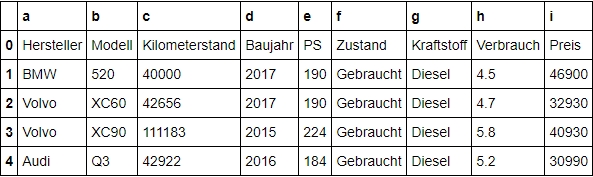
Jetzt wird die erste Zeile als Bestandteil der Daten behandelt. Wie du siehst, hat Pandas den Spalten automatisch einen Index aus Zahlen zugewiesen. Wir wollen aber beim Import direkt wieder neue Namen vergeben.
df = pd.read_excel("...DeinPfad/Auto.xlsx",
header=None,
names=["a","b","c","d","e","f","g","h","i"])
df.head()
Index angeben
Beim normalem Import weist Pandas dem DataFrame eine Zahlenindex zu. Du kannst allerdings auch eine Spalte angeben, die du als Index nutzen willst, und zwar mit dem Argument index_col.
df = pd.read_excel("...DeinPfad/Auto.xlsx",
index_col="Hersteller")

Jetzt ist die Spalte Hersteller der Index des DataFrames und du kannst die Daten entsprechend abfragen. Lassen wir uns mal alle Zeilen mit dem Hersteller Volvo ausgeben.
df.loc["Volvo"]

Spalten ignorieren
Es kann passieren, dass du von einer Excel-Datei nicht alle Spalten brauchst. Da du dich nicht mit mehr Daten als nötig herum schlagen willst, kannst du mit dem Argument usecols gezielt einzelne Spalten importieren. Probieren wir es mal aus.
Nur den Hersteller importieren:
df = pd.read_excel("...DeinPfad\Auto2.xlsx",
usecols=["Hersteller"])

Hersteller und Baujahr importieren:
df = pd.read_excel("...DeinPfad\Auto2.xlsx",
usecols=["Hersteller", "Baujahr"])

Achte darauf, dass du auch beim Import von nur einer Spalte diese als Liste übergibst. Die Funktion braucht hier ein Objekt, über das sie iterieren kann, also nicht die eckigen Klammern vergessen.
Zeilen ignorieren
Analog zu Spalten kannst du auch Zeilen beim Import ignorieren bzw. überspringen. Mit skiprows lässt du eine bestimmte Anzahl von Spalten am Anfang der Datei aus.
df = pd.read_excel("...DeinPfad\Auto2.xlsx",
skiprows=5)

Wir haben die ersten 5 Zeilen nicht importiert, dementsprechend besteht der resultierende DataFrame nur noch aus 15 Zeilen.
Mit skipfooter ignorierst du die letzte Zeile. In Excel-Dateien können dies oftmals Ergebniszeilen sein, die aggregierte Zahlen enthalten. Deshalb ist es sinnvoll, diese Zeile außen vor lassen zu können. Du kannst dem Argument allerdings auch größere Zahlen übergeben, um dementsprechend mehr Zeilen beim Import zu vernachlässigen.
df = pd.read_excel("...DeinPfad\Auto2.xlsx",
skipfooter=1)

Wie haben die letzte Zeile nicht importiert, der Volkswagen T6 fehlt also.
Zu guter Letzt kannst du mit nrows (ab Pandas Version 0.23.0) den Import auf eine festgelegte Anzahl von Zeilen begrenzen.
df = pd.read_excel("...DeinPfad\Auto2.xlsx",
nrows=10)

Damit haben wir nur die ersten 10 Zeilen importiert.
Fazit
Nun kennst du die wichtigsten und am häufigsten gebrauchten Funktionalitäten beim Import von Excel-Dateien. Im Allgemeinen können wir sagen: Wenn du eine Excel hast, dann gibt es auch einen Weg, diese sinnvoll mit Pandas nach Python zu importieren.
Wie du die ersten Schritte beim Analysieren von Datensätzen in Python angehst, findest du in meinem Artikel über deskriptive Statistik mit Pandas. Und wenn du alles über den Umgang mit und die Analyse von Daten in Python wissen willst, empfehle ich dir das unten stehende Buch von Wes McKinney – erschienen im O’Reilly Verlag.
Anzeige

In diesem Buch erfährst du auf über 400 Seiten, wie du…
- Daten einliest, bearbeitest und deskriptive Statistiken erstellst
- effizient mit ein- und mehrdimensionalen Arrays rechnest
- Datensätze visualisierst
- mit HTML-Code und Web-APIs interagierst, um selbst Daten zu minen (siehe mein Web Scraper)
- Zeitreihen analysierst
…und vieles mehr. Die Technologien, welche du meistern wirst, umfassen Numpy, Pandas, Matplotlib und andere nützliche Python-Packages.
Viel Spaß beim Analysieren! 
Eine Tasse Kaffee?
In diese Seite fließt viel Zeit und Energie. In mich fließt deshalb viel Kaffee. Falls dir der Beitrag also geholfen hat, findest du vielleicht noch ein bisschen Kleingeld zwischen deinen Sofakissen und möchtest mir einen Kaffee spendieren. 🙂
Hall Chris – sehr verständlich erklärt.
Danke und viele Grüße
Jürgen
Hallo! Chris!
Danke für die schnelle und gut beschriebene Übersicht. Viel Spaß mit dem Kaffee!
Danke dir! Super, dass es dir geholfen hat. 🙂