

Deskriptive Statistik mit Python und Pandas
Deskriptive (beschreibende) Statistik ist eine der essentiellen Methoden für die Analyse eines Datensatzes. Im Arbeitsablauf eines Analysten kommt sie direkt nach der Datensäuberung – oft sogar schon davor. Wie du mit dem Analysetool Pandas große Datensätze in wenigen Arbeitsschritten zusammenfasst, erfährst du hier.Deskriptive Statistik hat einige Überschneidungen mit der explorativen Datenanalyse, auch EDA genannt (Tutorials dazu findest du hier). Bei beiden Methoden will man sich mit einem Datensatz grundlegend vertraut machen, um erste Tendenzen oder Unregelmäßigkeiten zu erkennen – in der EDA liegt der Fokus jedoch stark auf Visualisierung. In diesem Tutorial soll es aber um die grundlegenden Kennzahlen gehen, welche man sich zu Beginn einer Analyse anschaut.
Pandas und Daten importieren
Um die Methoden deskriptiver Statistik kennen zu lernen, brauchen wir natürlich Daten. Als Beispieldaten nehmen wir einen Datensatz der University of California mit 398 Autos samt folgender Eigenschaften.
mpg: Miles per Gallon (Verbrauch) cylinders: Zahl der Zylinder displacement: Hubraum horsepower: PS weight: Gewicht acceleration: Beschleunigung year: Baujahr origin: Herkunft(1=USA, 2=Europa, 3=Asien) name: Modellname
Jetzt importieren wir das Modul Pandas und laden die Daten einen DataFrame – die grundlegende Datenstruktur in Pandas. Ein DataFrame ist eine Tabelle mit meist individuellen Spaltennamen und manchmal auch individuellem Index. Wie bei einer Excel- oder SQL-Tabelle können wir auch einen DataFrame beliebig formatieren und manipulieren. Wir können die Beispieldatei aus dem Internet direkt in unsere Tabelle namens df in Python laden.
import pandas as pd
df = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data",
delim_whitespace=True,
header=None,
names=["mpg",
"cylinders",
"displacement",
"horsepower",
"weight",
"acceleration",
"year",
"origin",
"name"])
Als Allererstes schaue ich mir immer die ersten 5 Zeilen an, um zu prüfen, ob der Import auch funktioniert hat.
df.head()
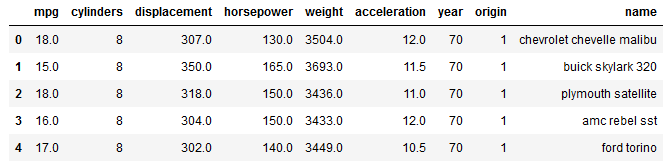
Sieht gut aus. Dann können wir direkt mit der deskriptiven Statistik fortfahren.
Daten auf fehlende Werte prüfen
Um herauszufinden, welche Eigenschaften deiner Daten aussagekräftig sind, lohnt es sich oft, die Anzahl der fehlenden Werte pro Spalte zu untersuchen.
df.isnull().sum()

Diesen Anblick wirst du nur sehr selten genießen dürfen. Jede Spalte der Tabelle ist komplett mit Werten befüllt. Bei unbearbeiteten Rohdaten ist dies so gut wie nie der Fall.
Datentypen prüfen
Jetzt schauen wir mal, ob auch alle Spalten den korrekten Datentyp besitzen. Manchmal sehen Daten erst mal korrekt aus, sind aber trotzdem im falschen Format. Mit als String formatierten Zahlen hat man bei Berechnungen keinen Spaß.
df.dtypes

Bis auf die Spalte horsepower sieht alles schick aus. Bei 6 Einträgen dieser Spalte fehlen zwar keine Werte, dafür steht dort ein „?„. Darauf müssen wir bei allen weiteren Rechnungen in dieser Spalte achten.
Die Daten grundlegend beschreiben
Die einfachste Methode für einen ersten Blick auf Statistiken ist der Befehl describe().
df.describe()
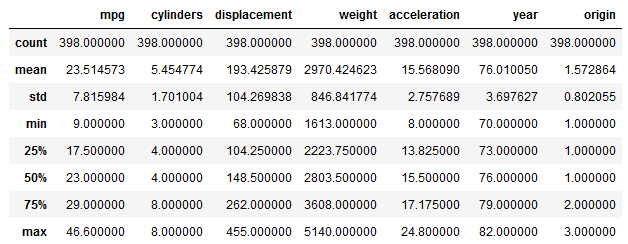
Standardmäßig zeigt dieser Befehl die Anzahl der Einträge, den Durchschnitt, die Standardabweichung, Minimum, Maximum sowie drei Perzentile für alle numerischen Spalten der Tabelle an. Die Perzentile können wir mittels einer Liste innerhalb der Funktion auch selbst definieren.
df.describe(percentiles=[.1,.2,.3,.4,.5,.6,.7,.8,.9])
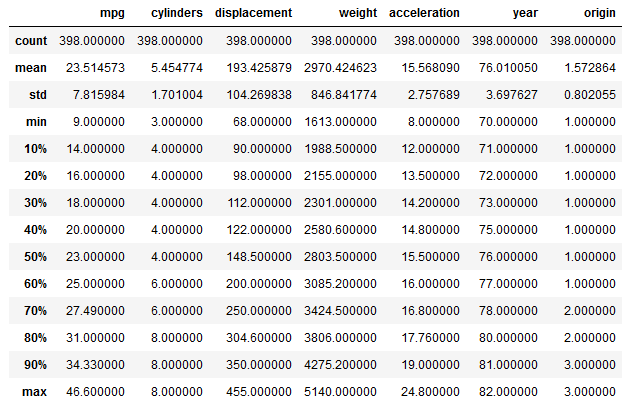
Zwei von zehn Fahrzeugen verbrauchen also in maximal 16 Meilen eine Gallone an Treibstoff.
Für die Spalten name und horsepower werden aufgrund ihres Datentyps keine Statistiken angezeigt. Dafür müssen wir einem der Argumente innerhalb der Funktion explizit einen bestimmten Wert zuweisen.
df.describe(include="all")
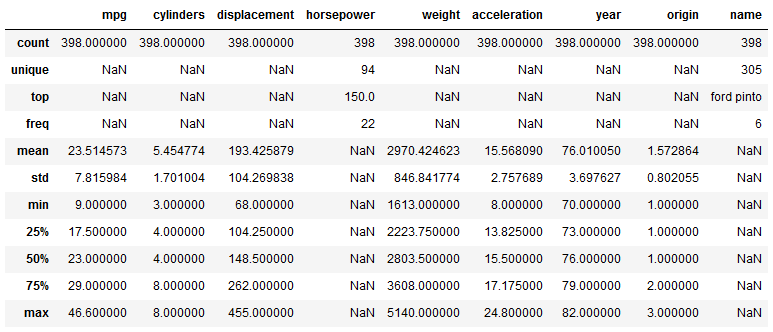
Jetzt werden unabhängig von den Datentypen alle Spalten des DataFrames angezeigt. Gleichzeitig sind nun drei neue Statistiken dazu gekommen. In der Spalte name bedeuten diese, dass es 305 unterschiedliche Modelle in den Daten gibt. Das am häufigsten vertretene Modell ist ein Ford Pinto, welcher 6-mal vorkommt. Da die Spalte nur Text enthält, werden dementsprechend keine Werte für Durchschnitt, Maximum etc. angezeigt. Um in der Spalte horsepower auch zusammenfassende Statistiken anzeigen zu lassen, können wir einen zweiten DataFrame ohne die störenden Einträge erstellen.
df2 = df.loc[df.horsepower!="?"].copy() df2.horsepower = df2.horsepower.astype(float) df2.describe(include="all")
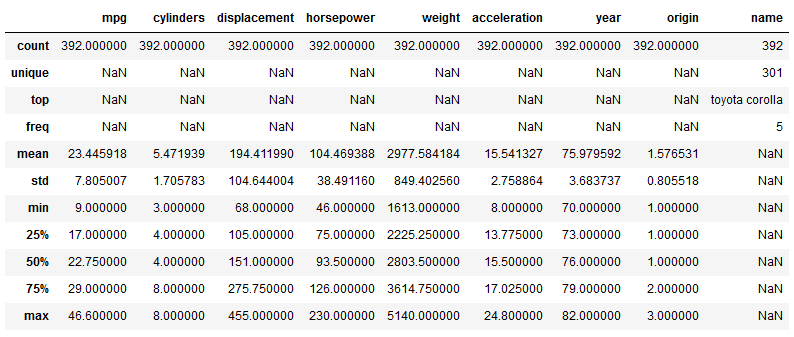
Jetzt sehen wir auch für horsepower entsprechende Kennzahlen. Für die weitere Analyse nutzen wir jedoch wieder den ursprünglichen DataFrame.
Häufigkeiten untersuchen
Häufigkeiten sind ein weiterer elementarer Bestandteil jeder Datenanalyse. Auch dafür hält Pandas die richtige Funktion bereit. Schauen wir uns zum Beispiel an, wie die Herkunftsorte der Autos im Datensatz verteilt sind.
df.origin.value_counts()
Von den 398 untersuchten Autos stammen also 249 aus den USA, 79 aus Asien und 70 aus Europa. Oft will man aber nicht nur die absoluten, sondern die relativen Häufigkeiten untersuchen. Dazu gibt es natürlich auch das passende Argument.
df.origin.value_counts(normalize=True)
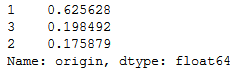
Nun können wir nämlich die Aussage treffen, dass knapp 63% der Autos aus den USA kommen. Prozentwerte sind meist aussagekräftiger als absolute Zahlen. Doch Achtung! Standardmäßig werden von dieser Funktion alle fehlenden Einträge ausgeschlossen. Ist also die halbe Spalte leer, würde einem das hier nicht auffallen. Um auch leere Werte anzuzeigen, muss man der Funktion noch ein weiteres Argument hinzufügen.
df.origin.value_counts(normalize=True,dropna=False)
Bei einer Spalte mit leeren Einträgen würde die Anzahl der fehlenden Werte unter NaN zusammengefasst werden. In unserem Beispiel ist das Ergebnis jedoch mit dem oben identisch, da die komplette Spalte mit Werten befüllt ist.
Mit der Funktion value_counts() kannst auch ganz leicht eine Top 10 eines bestimmten Merkmals aufstellen. Schauen wir uns mal die 10 am häufigsten vorkommenden Baujahre im Datensatz an.
df.year.value_counts(normalize=True)[:10]
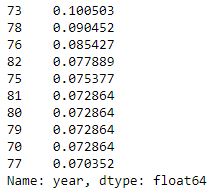
Hier sehen wir, dass das mit gut 10% am häufigsten vorkommende Baujahr 1973 ist, dicht gefolgt vom Baujahr 1978.
Fazit
Mit den gezeigten Pandas-Funktionen kannst du ganz einfach die zentralen Kennzahlen eines Datensatzes ermitteln und somit eine Grundlage für alle weiteren Analysen schaffen. Viel Spaß beim Nachmachen!