

Twitter Mining in Python mit Tweepy und der Twitter API
Mit 335 Millionen monatlich aktiven Nutzern ist Twitter eines der weltweit populärsten sozialen Netzwerke. Und genau das ist ein guter Grund, sich mal anzuschauen, wie man die digitale Datenflut analysieren kann.
Twitter als Datenoase
Der Erfolg von Twitter ist nicht zu bestreiten. Allein in den letzten 8 Jahren hat sich die Zahl der aktiven Nutzer mehr als verzehnfacht. Die Plattform wird nicht nur für private Zwecke genutzt, selbst im Bundestag hat die Mehrzahl der Mitglieder einen Twitter-Account. Für Analysten bietet sich hier unglaubliches Potential – Tweets analysieren, Nutzer und deren Followerzahl untersuchen, Netzwerkanalysen aufstellen und vieles mehr. Doch dies geht nur, falls man schnell an die relevanten Daten kommt, ohne ganze Tage bei Twitter zu verbringen und die Daten händisch zu sammeln. Zum Glück gibt es die Twitter API. Mit ihrer Hilfe kannst du beinahe alles analysieren, was du auf der Plattform siehst.
Voraussetzungen der Twitter API
Damit Twitter weiß, wer sich gerade die Daten zieht, musst du dich bei der API zuerst authentifizieren (mehr dazu später). Dafür brauchst du einen Twitter-Account – jedoch keinen normalen, sondern einen Developer-Account. Falls du schon ein Twitter-Nutzer bist, kannst du den Entwickler-Account hier einrichten. Sobald du damit fertig bist, erstellt du hier deine erste sogenannte Twitter-App. Nach der Erstellung findest auf der unten gezeigten Hauptseite deiner App im Reiter Keys and Access Tokens alle Zugangsschlüssel zur API, die du brauchst – Consumer Key (API Key), Consumer Secret (API Secret), Access Token und Access Token Secret.
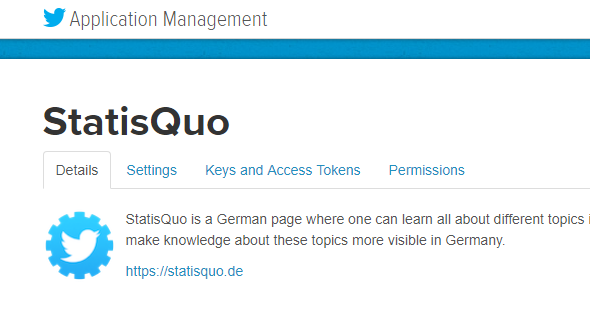
Twitter API und Tweepy in Python
Von Twitters Seite haben wir nun alle Voraussetzungen erfüllt. Jetzt kommt die Arbeit in Python. Hier gibt es zum Glück schon ein Framework namens Tweepy, mit dessen Hilfe wir in Python mit der Twitter API interagieren können und das sich ganz normal mit pip (Das Standard-Package zum Managen von Python-Modulen) installieren lässt. Dann kann’s auch schon losgehen. Wie immer importieren wir zuerst das benötigte Modul.
import tweepy
Nun erstellen wir Variablen für die Zugangsschlüssel (die du mit deinen persönlichen Codes befüllst) und erstellen ein API-Objekt.
consumer_key="XXXXXXXXXXXXXXXXXXXX" consumer_secret="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" access_token="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" access_token_secret="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth)
Beiträge auf meiner Twitter-Startseite
Jetzt können wir auch schon die ersten Daten von Twitter ziehen. Schauen wir uns mal die neusten Beiträge auf meiner Startseite von StatisQuo an.
home_tweets = api.home_timeline(count=10)
for tweet in home_tweets:
print(tweet.text)
print("")
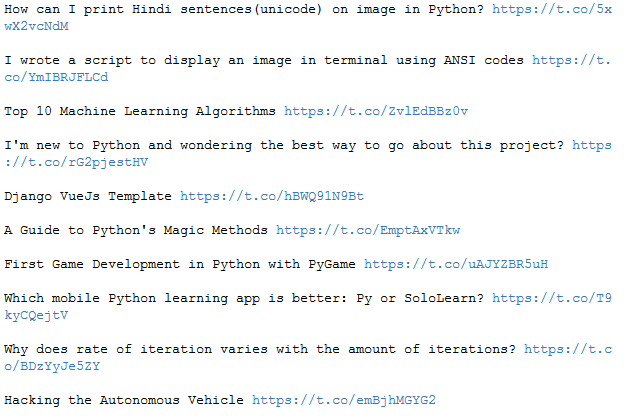
Standardmäßig werden die 20 aktuellsten Tweets auf der eigenen Startseite ausgegeben. Mit dem Argument count kannst du die Anzahl erhöhen oder einschränken. Der Tweet-Text ist jedoch nicht alles, was du sehen kannst.
Gesamtes Tweet-Objekt abfragen
Mit der Methode _json kannst du dir das gesamte Tweet-Objekt anzeigen lassen.
api.home_timeline()[0]._json
Für eine übersichtlichere Darstellung kannst du den obigen Befehl als Argument der Funktion dumps() des Python-Pakets namens json übergeben.
import json print(json.dumps(api.home_timeline()[0]._json,indent=4))
Das Ganze sieht dann so aus.
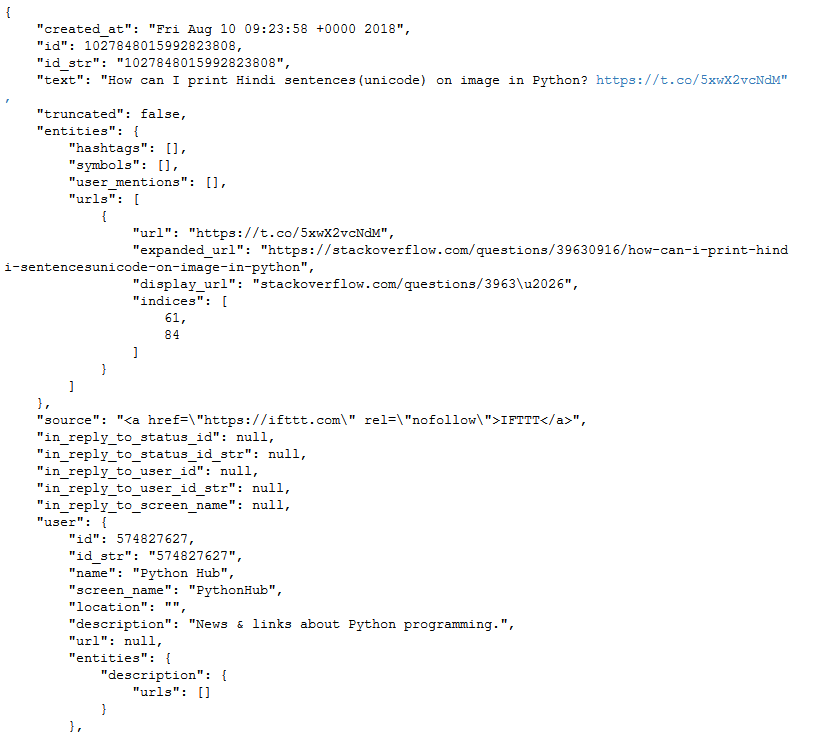

Es lässt sich also noch sehr viel mehr an Information aus einem Tweet gewinnen als nur der reine Text: Der User, die Zahl seiner Follower und Freunde, ob und wie oft der Post retweetet wurde, ob man selbst dem Account folgt und vieles mehr. Natürlich kannst du nicht nur die Tweets in deiner eigenen Timeline analysieren, sondern die jedes beliebigen anderen Nutzers.
Tweets und Freunde anderer Nutzer
Unten siehst du zum Beispiel die 10 aktuellsten Tweets aus der Timeline des Postillons.
for item in tweepy.Cursor(api.user_timeline,
id="Der_Postillon",
tweet_mode="extended").items(10):
print(item._json["full_text"])
print("")
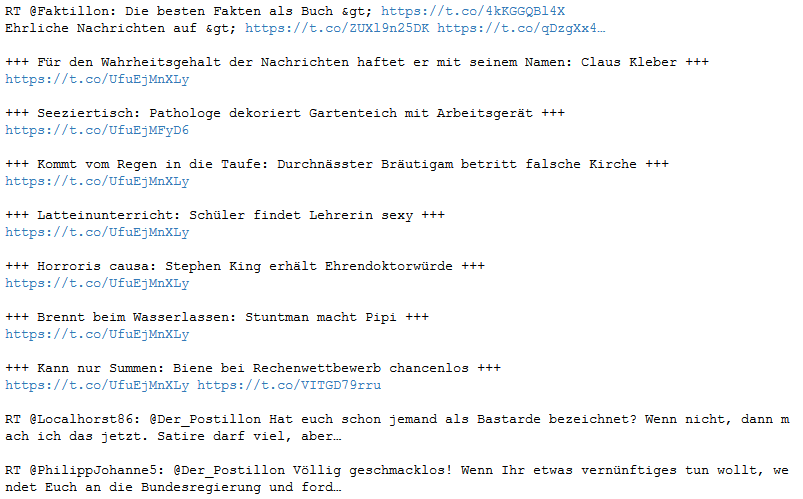
Über die friends-Methode des API-Objekts kannst du dir zudem die Freunde eines bestimmten Nutzers anschauen. Auch hier habe ich die Auswahl auf 10 beschränkt.
for friend in tweepy.Cursor(api.friends, id="Der_Postillon").items(10):
print(friend._json["screen_name"])

Eigenschaften eines Nutzers
Außerdem besitzt das API-Objekt von Tweepy eine Methode get_user, mit deren Hilfe wir allerlei Dinge über andere Nutzer erfahren können. Unten siehst du einige Beispiele.
user = api.get_user('Der_Postillon')
print("Anzahl Follower: "+str(user.followers_count))
print("Anzahl Freunde: "+str(user.friends_count))
print("Account erstellt am: "+str(user.created_at))
print("Beschreibung: "+str(user.description))
print("Name: "+str(user.name))
print("Screen-Name: "+str(user.screen_name))
print("Anzahl Tweets: "+str(user.statuses_count))
print("Verifizierter Nutzer: "+str(user.verified))

Selbst Beiträge verfassen
Durch die Schnittstelle kannst du nicht nur Daten ziehen, sondern auch selbst Tweets veröffentlichen. Und so einfach geht’s:
api.update_status("Hallo Welt!")
Und schon ist der Tweet in meiner Timeline zu sehen. Zusätzlich zum Erstellen eigener Tweets hast du die Möglichkeit, Posts von anderen Nutzern zu retweeten – und zwar so:
api.retweet(1027563874395074560)
Soeben haben wir diesen Beitrag retweetet. Alles, was du dafür brauchst, ist die Tweet-ID, welche sich am Ende der URL des jeweiligen Beitrags befindet.
Noch mehr Möglichkeiten
Die oben gezeigten Funktionen sind nur ein Teil der Möglichkeiten, die es gibt, um mit der API zu arbeiten. Die gesamte Anleitung für die Benutzung von Tweepy findest du hier. Allgemein gesprochen kannst du alles, was du normalerweise über die Oberfläche von Twitter machst, auch mit Hilfe der Schnittstelle tun. Für datenhungrige Analysten sind die wertvollsten Funktionen natürlich diejenigen, mit denen man im großen Stil Daten von Twitter strukturiert herunterladen und untersuchen kann.
Anwendungsbeispiele
Soziale Netzwerke sind wie gemacht für – wer könnte es ahnen – Netzwerkanalysen. Eine ähnliche Analyse wie im Beitrag zu Harry Potter könnte man auch für Twitter-Nutzer anstellen. Zum Beispiel könnte man sich anschauen, welche Bundestagsmitglieder welchen anderen Bundestagsmitgliedern folgen oder Mitglieder miteinander befreundet sind. Außerdem könntest du herausfinden, wo auf der Welt welche Themen gerade heiß diskutiert werden. Wenn du schon etwas fortgeschritten bist, dann probiere doch mal eine Sentiment-Analyse anhand von Textinhalten der Beiträge aus – wie zum Beispiel Melanie Siegel et al. es getan haben. Die Möglichkeiten für Analysen, Visualisierungen und die Anwendung von Machine Learning sind gigantisch.
Viel Spaß beim Nachmachen!