

Harry Potter und die Netzwerkanalyse in Python
Wir alle kennen Netzwerke. Seien es soziale Netzwerke wie Facebook und Twitter, S-Bahn-Netze oder Stromnetze. Wie du sie visualisierst, erfährst du in diesem Beitrag.
Knoten und Kanten
Wenn du dieser Beitragsreihe gefolgt bist, dann kennst du schon viele Möglichkeiten der Datenvisualisierung – wie zum Beispiel Scatterplots, Boxplots oder Histogramme. Je nach Fragestellung sind diese Diagramme hervorragende Werkzeuge, um mehr über Zusammenhänge in einem Datensatz zu erfahren. Doch welche Methoden gibt es, um Interaktionen oder soziale Beziehungen darzustellen? Die Antwort sind Graphen! Laut Wikipedia ist ein Graph eine abstrakte Struktur, die eine Menge von Objekten zusammen mit den zwischen diesen Objekten bestehenden Verbindungen repräsentiert. Die Objekte werden hierbei als Punkte (Knoten) dargestellt, während ihre Beziehungen zueinander durch Linien (Kanten) gekennzeichnet sind.
Knoten können ganz verschiedene Dinge sein. Facebook-Freunde, Bahnhöfe, Produktionsstandorte oder Charaktere eines Romans. Womit wir auch schon bei Harry Potter wären. Anhand der Buchreihe über einen jungen Zauberer schauen wir uns an, wie man das soziale Netzwerk dieser Romanfiguren anschaulich darstellen kann.
Das Ziel der Analyse
Unser Ziel soll es sein, die Beziehungen zwischen den einzelnen Charakteren zu visualisieren – und zwar in der Art und Weise, dass man leicht erkennen kann, welche Figuren im Roman besonders oft zusammen auftauchen und welche eher selten. Dafür schauen wir uns den Text an und untersuchen für jede Figur A, wie oft eine Figur B in einem Abstand von höchstens X Wörtern zu Figur A genannt wird. Je öfter die Figuren A und B zusammen genannt werden, desto stärker ist ihre Beziehung zueinander. Die Stärke der Beziehung drücken wir in einem Score aus, welcher angibt, wie oft die beiden Figuren zusammen erscheinen. Der Graph wird dann vom Score dahingehend beeinflusst, dass Kanten mit höherem Score dicker sind und Knoten mit mit einer dickeren Kante näher aneinander liegen.
Die Daten beschaffen
Wie immer brauchen wir zuerst natürlich Rohdaten. Das heißt in diesem Fall, dass wir die Bücher (am besten als Textdatei) irgendwoher bekommen müssen. Nichts leichter als das. Auf dieser Seite kannst du alle Bücher der Reihe im passenden Format herunterladen. Der Einfachheit halber befassen wir uns vorerst nur mit Teil 1. Was wir außerdem brauchen, ist eine Liste von Figuren, welche wir untersuchen wollen. Diese Liste habe ich manuell erstellt, indem ich die Charaktere von hier in eine Excel-Datei kopiert habe (und die deutsche Hermine zur englischen Hermione gemacht habe). Uns liegen jetzt also sowohl eine Textdatei des ersten Bands von Harry Potter als auch eine Excel-Tabelle mit allen Figuren vor.
Die Daten vorbereiten
Lesen wir erst einmal beide Dateien in unsere Programmierumgebung. Das Buch ist zwar eine Textdatei, besteht aber aus HTML-Code. Deshalb importiere ich die Datei mit Hilfe des Moduls Beautifulsoup und extrahiere den Text zwischen den pre-Tags. Dort steht nämlich der eigentliche Text des Romans.
from bs4 import BeautifulSoup
import pandas as pd
with open(".../Book 1.txt","r",encoding="utf-8") as file:
hp1 = bs.BeautifulSoup(file,"lxml")
hp1 = str(hp1.find_all("pre")).replace("\n"," ")
fig = pd.ExcelFile(".../charaktere.xlsx").parse(0)
Das Objekt hp1 besteht aus einem einzigen langen String. Die ersten 1.000 Zeichen des Textes sehen so aus.
hp1[:1000]

Schauen wir uns mal einen Teil der Charaktere an.
fig[:25]
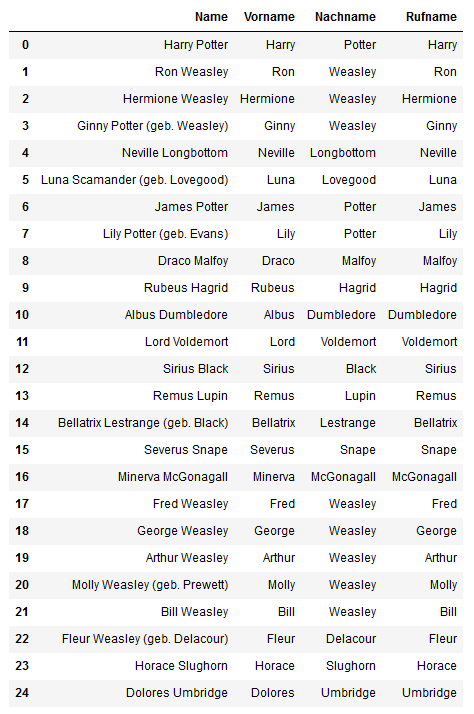
In die Spalte Rufname habe ich für jede Figur den Namen eingetragen, der (nach Bauchgefühl) am häufigsten genannt wird. Wir brauchen ja eine Liste mit Wörtern, nach denen im Text gesucht werden soll. Dafür ist es wenig sinnvoll, immer den vollen Namen, nur den Vornamen oder nur den Nachnamen zu nutzen. Natürlich ist auch diese Herangehensweise nicht zu 100% präzise. Zum Beispiel wird Ron von Lehrern oft als Mr. Weasley angesprochen, diese Fälle werden jedoch von unserem Programm ignoriert werden. Trotzdem haben wir mit der Liste eine gute Annäherung. Und diese Liste erstellen wir jetzt.
char_list = list(fig.Rufname.str.lower())
Außerdem müssen wir den Buchtext noch so formatieren, dass wir keinen einzigen langen String, sondern eine Liste aus einzelnen Wörtern haben. Für unser Vorhaben ist es weiterhin sinnvoll, alle Zeichen, die keine Buchstaben sind, aus dem Text zu entfernen. Dafür nutzen wir das Modul re für Regular Expressions und splitten den String dann bei jedem Leerzeichen.
hp1_str_split = re.sub(pattern='\W+',
string=hp1.lower(),
repl=" ").split(" ")
Das Ergebnis des Befehls ist nun eine Liste mit 84.449 Einträgen. Schauen wir uns mal die ersten 50 Einträge an.
print(hp1_str_split[:50])

Gleichzeitig haben wir den Text – wie oben auch schon die Namensliste – in Kleinbuchstaben umgewandelt, um auch komplett sicher zu gehen, dass alle Namen beim Iterieren über den Text erwischt werden.
Das Skript
Für ein funktionierendes Skript brauchen wir zuerst die Paare von Figuren, deren Beziehungen untersucht werden sollen. Doch wie viele und welche unterschiedlichen Paare gibt es für die Liste von Charakteren überhaupt? Für dieses Problem gibt es das nette Python-Package itertools. Damit können wir innerhalb des Skripts über alle Kombinationen aus Figuren iterieren und dann Scores berechnen. Das Skript sieht dann folgendermaßen aus.
from itertools import combinations
char=[]
score=[]
umkreis=50
for paar in combinations(char_list,2):
zw_summe = 0
for i in range(len(hp1_str_split)):
if hp1_str_split[i]==paar[0]:
for k in [x for x in hp1_str_split[i-umkreis:i+umkreis]]:
if k == paar[1]:
zw_summe+=1
char.append(paar)
score.append(zw_summe)
df = pd.DataFrame({"char":char,
"score":score})
Erst definieren wir die zwei Listen char und score, in die später jeweils das Charakterpaar und der dazu gehörende Score geschrieben wird. Dann iterieren wir über die Liste der Kombinationen von Figuren. Nehmen wir als Beispiel die Kombination Harry und Ron. Das Skript durchsucht den Buchtext nach Harry. Für jeden Eintrag namens Harry schaut es in einem Umkreis von 50 Wörtern vor und nach dem Eintrag, wie oft auch Ron genannt wird. Für jeden Treffer erhöht sich die Zwischensumme (zw_summe) um 1. Zum Schluss wird die Liste char um das Tupel (Harry, Ron) erweitert und die Liste score um die dazu gehörige Trefferzahl. Zum Schluss schreiben wir beide Listen in den DataFrame df. Schauen wir uns mal die Top 10 der häufigsten Kombinationen an.
df.sort_values(by="score",ascending=False)[:10]

Die stärkste Beziehung zueinander scheinen Harry und Ron zu besitzen. Außerdem erscheint Harry als Hauptcharakter des Buches in jeder der 10 häufigsten Kombinationen.
Damit haben wir die Vorbereitung der Daten hinter uns. Mit dem DataFrame liegen uns nun die benötigten Kanten und Gewichtungen vor, welche wir für die Erstellung eines Graphen brauchen.
Den Graphen bauen
Für die Erstellung und Visualisierung des Graphen nutzen wir das Package NetworkX. Zuerst generieren wir einen leeren ungerichteten Graphen G.
import networkx as nx G = nx.Graph()
Als nächstes generieren wir zwei Listen. Eine mit Kanten und eine mit Gewichtungen. Dabei nehmen wir jedoch nur Kombinationen von Figuren, welche mindestens einmal zusammen vorkommen – also einen Score größer 0 besitzen.
edges = list(df.loc[(df.score>0)].char) weights = list(df.loc[(df.score>0)].score)
Nun können wir die Kanten dem Graphen G hinzufügen.
G.add_edges_from(edges)
Und fertig ist der Graph. Diesen können wir jetzt visualisieren, wobei die Gewichtungen erst hier an das Objekt übergeben werden.
import matplotlib.pyplot as plt
nx.draw(G,
width=[(weight/2)**0.5 for weight in weights],
with_labels=True,edge_color="green",
node_size=[(weight*15000)**0.5 for weight in weights],
node_color="lightgrey",
node_shape="o",
font_size=10,
font_color="black",
alpha=0.9)
plt.show()
Mit den Argumenten der draw()-Funktion kannst du beliebig spielen. Oft muss man sie manuell anpassen und genau justieren, um den Graphen auch optisch ansprechend zu gestalten. Hier findest du alle veränderbaren Argumente für die Funktion. Das Ergebnis sieht so aus.
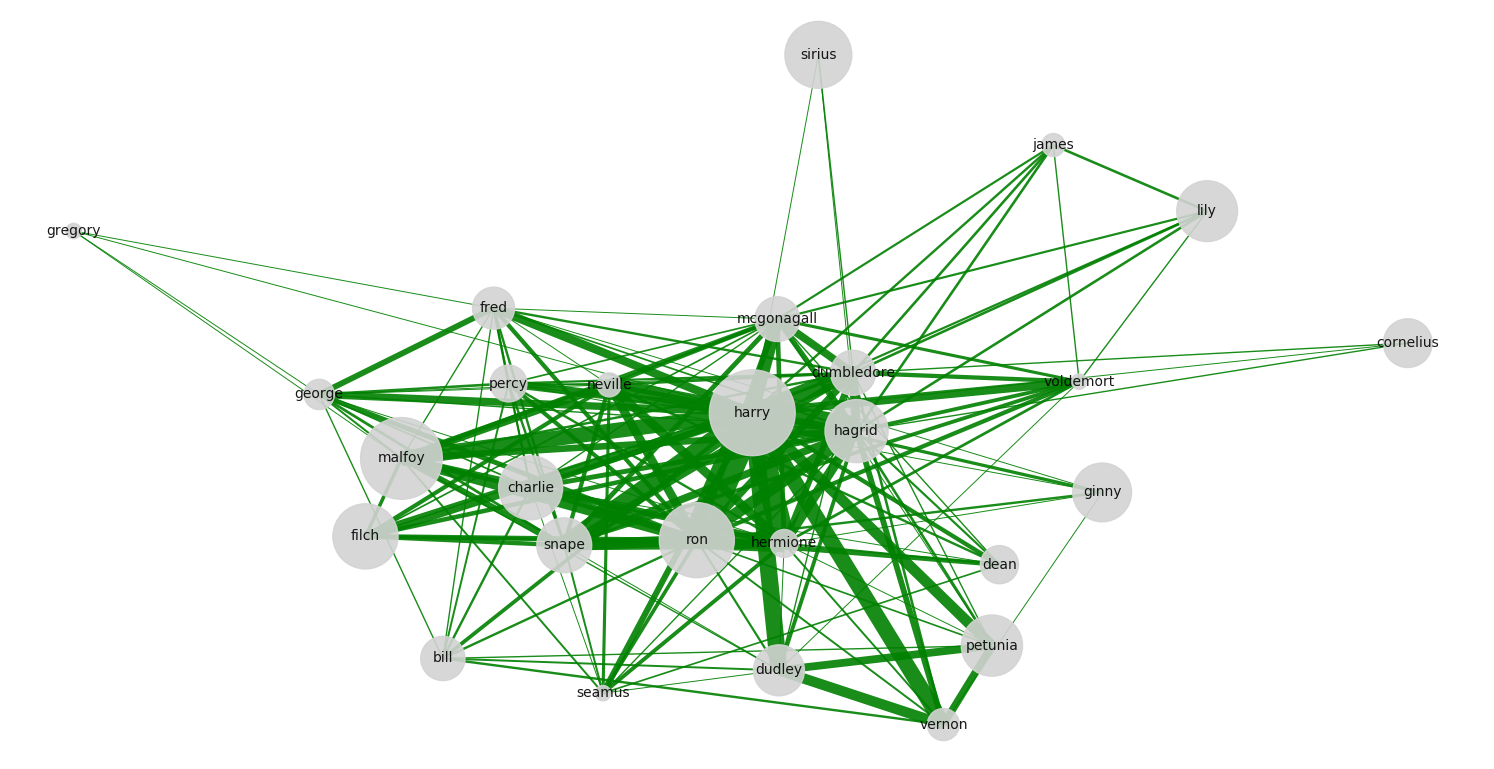
Man sieht klar, dass Harry der Protagonist des Buches ist, mit starken Beziehungen zu Ron und Hagrid – aber im Grunde genommen verbunden mit allen anderen Figuren. Unten rechts versammelt sich die komplette Familie Dursley (Sohn Dudley, Vater Vernon, Mutter Petunia) und links dicht beieinander sehen wir einen großen Teil der Weasley-Familie (Fred, Percy, George, Charlie). Charaktere, die im Buch inhaltlich zusammenhängen, tauchen also auch im Graphen gebündelt auf. Andererseits erkennt man, welche Figuren nichts miteinander zu tun haben – wie zum Beispiel Ginny Weasley und Lily Potter. Zwischen den beiden könnte es aber keine Verbindung geben, wenn man den oben definierten Suchbereich von 50 auf 250 Wörter vergrößern würde. Ab einer gewissen Größe wären alle Figuren miteinander vernetzt, dies würde der Graphenanalyse allerdings ein wenig den Sinn nehmen.
Fazit
Der größte der Teil der Arbeit für die Netzwerkanalyse war in diesem Fall die Vorbereitung der Daten. Hast du erst mal eine fertige Grundstruktur, dann kannst du mit NetworkX und wenigen Zeilen Code einen Graphen erstellen und visualisieren. Dabei hast du jede Menge Möglichkeiten, den Graphen an deine Anforderungen anzupassen.
Alternativ zur Analyse oben könntest du auch die Beziehungen zwischen Zauberern und Zaubersprüchen untersuchen. Welcher Charakter nutzt welchen Spruch besonders oft? Oder du analysierst einen anderen Text deiner Wahl. Die Möglichkeiten stehen dir offen. Viel Spaß beim Nachmachen!
Ich habe den Code übernommen, aber ich bekomme für meine Daten immer die Fehlermeldung: „s must be a scalar, or the same size as x and y“, und wenn ich die Zeile „G.add_edges_from(edges)“ auskommentiere, bekomme ich einen leeren Graphen angezeigt. Was ist da los?
Mein Script
import os
import os.path
from os import walk
import nltk
from itertools import combinations
import pandas as pd
import re
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
#mydir = ‚H:/Documents/EIGENE PYTHONS/NLTK/data/‘
mydir = „/Users/annettevowinckel/Python/0_eigene_codes/Zentralbild_Annette/“
char_list=[]
f = open(mydir + ‚Netzwerke/ZB_Namen_kurz.csv‘, ‚r‘)
for line in f:
line = line.rstrip()
name = line.split(‚,‘)[0]
if len(name) > 0:
if not name == „\ufeffAdam“:
char_list.append(name)
else:
char_list.append(„Adam“)
print(len(char_list))
f.close
file = mydir+“data/zb_string_gesamt.txt“
f = open(file,“r“,encoding=“utf-8″)
filewords = f.read()
filewords.replace(„\n“,“ „)
allwords=filewords.split()
print(„filewords: „, len(filewords))
chars=[]
scores=[]
umkreis = 100
for char in combinations(char_list,2):
score = 0
oclist = [m.start()for m in re.finditer(char[0], filewords)]
# print(char[0],oclist)
for oc0 in oclist:
oc1 = filewords.find(char[1],oc0-umkreis,oc0+umkreis)
if oc1 > -1:
# print(filewords[oc1:oc1+10])
score+=1
if score > 0:
chars.append(char)
scores.append(score)
print(char, score)
df = pd.DataFrame({„chars“:chars,
„scores“:scores})
df = df.sort_values(by=“scores“,ascending=False)[:14]
print(‚Daten gesammelt, jetzt noch visualisieren‘)
G = nx.Graph()
edges = list(df.loc[(df.scores>0)].chars)
weights = list(df.loc[(df.scores>0)].scores)
G.add_edges_from(edges)
nx.draw(G,
width=[(weight/2)**0.5 for weight in weights],
with_labels=True,edge_color=“green“,
node_size=[(weight*15000)**0.5 for weight in weights],
node_color=“lightgrey“,
node_shape=“o“,
font_size=10,
font_color=“black“,
alpha=0.9)
plt.show()
df gibt folgendes Ergebnis:
char score
12 (Frotscher, Quaschinsky) 59
11 (Frotscher, Heilig) 57
15 (Heilig, Quaschinsky) 40
9 (Butenhoff, Quaschinsky) 31
4 (Baumgart, Heilig) 23
6 (Butenhoff, Frotscher) 23
5 (Baumgart, Quaschinsky) 10
8 (Butenhoff, Heilig) 10
3 (Baumgart, Frotscher) 9
2 (Baumgart, Butenhoff) 7
10 (Frotscher, Gottwald) 5
13 (Gottwald, Heilig) 5
14 (Gottwald, Quaschinsky) 4
1 (Bach, Heilig) 2
Liegt wohl an der Zeile „node_size = …“. Wenn man die aaskommentiert läuft es, aber weshalb… weiß ich auch nicht.
This might be a solution:
The length of the array of node_size has to me the the same as the number of nodes.
# create a variable with the number of nodes
number_of_nodes = G.number_of_nodes()
# slice the array of weights to get the correct length.
weights_nodes = weights[:number_of_nodes]
nx.draw(G,
width=[(weight/2)**0.5 for weight in weights],
with_labels=True,edge_color=“green“,
node_size=[(weight*15000)**0.5 for weight in weights_nodes ],
node_color=“lightgrey“,
node_shape=“o“,
font_size=10,
font_color=“black“,
alpha=0.9)
plt.show()
Hey Paul, thanks for your input! Worked like a charm.