

Neuronale Netze ganz einfach mit Keras/TensorFlow
Neuronale Netze sind momentan die am meisten gefeierte Technologie im Bereich Machine Learning / Künstliche Intelligenz – und das zu Recht! Wie du in 10 Minuten in Python ein neuronales Netz baust, erfährst du in diesem Beitrag.
Was du dafür brauchst
Um das folgende neuronale Netz zu bauen, brauchst du zum einen TensorFlow und zum anderen Keras – beide kannst du leicht mit pip installieren. TensorFlow ist sozusagen der Motor des Modells. Hier findet der Lernprozess statt, bei dem das neuronale Netz optimiert wird. Diese Programmbibliothek taucht zwar nirgends im Code auf, wird aber trotzdem von Keras als Backend benötigt. Keras ist das in Python geschriebene und leicht zu bedienende Armaturenbrett, mit dessen Hilfe wir das Modell definieren und es dann an TensorFlow übergeben. Außerdem brauchst du sklearn, um die Rohdaten in Trainings- und Testdaten zu splitten. Der Schritt ist zwar nicht unbedingt notwendig, um mit neuronalen Netzen zu spielen, jedoch ist der Test eines statistischen Modells an „neuen“ Daten aussagekräftiger als an Daten, mit denen der Algorithmus zuvor schon trainiert wurde.
Modul importieren und Daten vorbereiten
Erst mal importieren wir alle benötigten Module und Funktionen.
from keras.models import Sequential from keras.layers import Dense from sklearn.model_selection import train_test_split
Wir bauen ein simples neuronales Netz mit einer versteckten Schicht (engl.: „hidden layer“). Hierbei sind alle Inputvariablen mit allen Knoten der versteckten Schicht verbunden. Der Einfachheit halber gibt es in der versteckten Schicht genauso viele Knoten wie es Inputvariablen gibt. Diese Knoten wiederum sind mit einem Output verbunden. Unten siehst du eine schematische Darstellung.
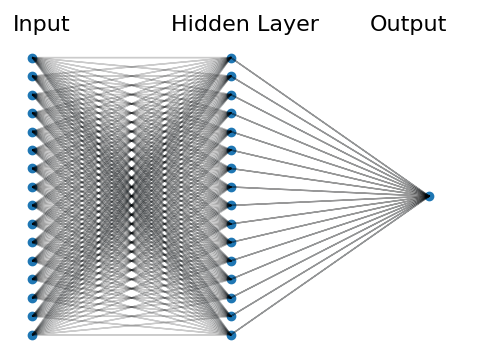
Als nächstes spielen wir die Daten ein und definieren die Trainings- und Testdaten. Als Beispiel nehme ich einen Auszug aus den Wohnungsdaten aus dieser Beitragsreihe. Unser Ziel ist es, mit Hilfe des neuronalen Netzes vorherzusagen, ob sich in einer neu zu vermietenden Wohnung schon eine Küche befindet oder nicht. Folgende Variablen stehen uns für das Training zur Verfügung.
X: Balkon_vorhanden, Barrierefrei, Kaltmiete, Etage, Keller_vorhanden, Garten_vorhanden, Letzte_Renovierung, Wohnflaeche, Ist_Neubau, Anzahl_Parkplätze, Anzahl_Zimmer, Warmmiete, Baujahr, Aufzug_vorhanden, Etagen_Gesamt, Betreutes_Wohnen y: Kueche_vorhanden
Die Variablen X und y liegen schon als Numpy-Arrays vor und müssen nur noch in Trainings- und Testdaten gesplittet werden. Dabei nutzen wir 80% der Daten für das Training und testen dann das Modell mit den restlichen 20%.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
Das Modell
model = Sequential() model.add(Dense(16, input_dim=X_train.shape[1], kernel_initializer='normal', activation='relu')) model.add(Dense(1, kernel_initializer='normal',activation='sigmoid'))
Mit der Funktion Sequential() bauen wir ein Modell, bei dem wir manuell Schicht für Schicht zum neuronalen Netz hinzufügen können. Das tun wir mit der Methode add(), in der wir die Art der Schicht definieren. In diesem Fall fügen wir mit Dense() eine reguläre Schicht hinzu, bei der jeder Knoten dieser Schicht mit jedem Knoten der nächsten Schicht verbunden ist. Innerhalb dieser Funktion definieren wir zunächst die Anzahl der Knoten (16) und die Anzahl der Inputvariablen (dieser Schritt ist nur in der ersten Schicht notwendig). Außerdem bestimmen wir mit dem Argument kernel_initializer den Anfangszustand aller Gewichtungen zwischen den Knoten, welche während des Trainings optimiert werden. Mit Hilfe des Arguments activation bestimmen wir zuletzt noch, wie jeder Knoten der Schicht auf den jeweiligen Input reagiert (mehr zu Aktivierungsfunktionen gibt es hier).
Der ersten und einzigen versteckten Schicht fügen nun noch eine weitere „Schicht“ hinzu. Sie entspricht dem Output und weil wir nur an einer Zahl (o oder 1) interessiert sind, besitzt diese Schicht auch nur einen Knoten.
Das Modell kompilieren, trainieren und testen
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
Bevor wir das Modell trainieren, muss es erst kompiliert werden. Hier definieren wir kurz gesagt, wie der Lernprozess ablaufen soll. Wir sagen dem Algorithmus, welche Fehlerfunktion auf welche Art und Weise minimiert werden soll und welche Kennzahl während der Optimierung ausgegeben werden soll. Danach können wir das Modell auch schon trainieren.
model.fit(X_train, y_train, epochs=10, batch_size=25)
Wir schieben die kompletten Daten insgesamt 10-mal durch das neuronale Netz. In jedem dieser Durchgänge werden die Daten in Batches (deutsch: „Stapel“, „Stoß“, „Ladung“) von je 25 Instanzen – in unserem Fall 25 Wohnungen – in das Netz eingespeist. Nach jedem Batch wird eine Fehlerfunktion berechnet und die Gewichte zwischen den Knoten werden entsprechend angepasst, sodass der Schätzfehler kleiner wird. Während der Algorithmus arbeitet, wird der Fortschritt vom Programm ausgegeben. Rechts siehst du in jeder Zeile die den momentanen Accuracy Score des Modells.

Nach 10 Durchgängen hat unser Modell eine Präzision von über 98% erreicht. Bei fast allen Wohnungen kann das neuronale Netz zuverlässig schätzen, ob eine Wohnung schon eine Küche beinhaltet oder nicht. Jetzt werfen wir dem Modell noch die Testdaten vor – also die 20% des Datensatzes, welche wir dem Modell bis jetzt vorenthalten haben.
score = model.evaluate(X_test, y_test)
print("Accuracy Score: "+str(round(score[1],4)))
Accuracy Score: 0.999
Auch auf den Testdaten performt das neuronale Netz mit einer Präzision von mehr als 99% sehr gut.
Zusammenfassung
So einfach kann der Einstieg in die heißeste Technologie im Umfeld von Machine Learning und künstlicher Intelligenz sein. Wir haben in kürzester Zeit ein neuronales Netz programmiert, das anhand von 16 Features einen binären Klassifikator baut und prognostiziert, ob sich in einer neu vermieteten Wohnung schon eine Küche befindet oder nicht. Das hier war nur ein kleines Basismodell. Mit Keras kannst du natürlich noch viel ausgefeiltere und komplexere Modelle bauen. Also viel Spaß beim Programmieren!



Erstmal vielen Dank für dein Tutorial!
Als blutiger Anfänger in diesem Bereich hat es mir so einige Dinge erklärt allerdings habe ich das noch nicht ganz zum laufen gebracht. Sobald ich das Model trainieren will, bekomme ich Fehlernmeldungen der Art „Error when checking input: expected dense_69_input to have shape (16,) but got array with shape (1,)“ um die Ohren geworfen.
Du sprichst ja davon das folgende Variable schon als Numpy-Array vorliegen:
X: Balkon_vorhanden, Barrierefrei, Kaltmiete, Etage, Keller_vorhanden, Garten_vorhanden, Letzte_Renovierung, Wohnflaeche, Ist_Neubau, Anzahl_Parkplätze, Anzahl_Zimmer, Warmmiete, Baujahr, Aufzug_vorhanden, Etagen_Gesamt, Betreutes_Wohnen
y: Kueche_vorhanden
Kannst du hier eventuell etwas detaillierter darauf eingehen und erklären wie die Arrays genau initialisiert werden müssen bzw. das shape Property für die zwei Arrays jeweils auszusehen hat? In meinem Fall (mit einer Hand voll Testdaten), spuckt er mir (56,) aus.
X = np.array([„Balkon_vorhanden“,“ Barrierefrei“, „Kaltmiete“, „Etage“, „Keller_vorhanden“, „Garten_vorhanden“, „Letzte_Renovierung“, „Wohnflaeche“, „Ist_Neubau, Anzahl_Parkplätze“, „Anzahl_Zimmer“, „Warmmiete, Baujahr“, „Aufzug_vorhanden“, „Etagen_Gesamt, Betreutes_Wohnen“];
Y= np.array([„Kueche_vorhanden“]);
X.shape; // Gibt an wieviele Eigenschaften das Array hat: expected (18,)
Y.shape; // expected (1,)
Der Rest müsste es mit dem Code funktionieren. Ich habs leider nicht selber testen können.
Hoffe konnte einwenig helfen
Vielen Dank für deine Erläuterungen. Ich meine, alles identisch abgewickelt zu haben, stoße aber vor das Problem, dass meine Accuracy dauerhaft 0.000 ist. Könntest du mir vielleicht in der Sache helfen?
Fehlerbeschreibung:
0. Die entsprechenden Imports habe ich.
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense
1. Folgende Arrays werden verwendet:
X (drei unabhängige Variablen)
array([[Zahl Spalte 1 Zeile i, Zahl Spalte 2 Zeile i, Zahl Spalte 3 Zeile i],
…], dtype=object)
> 1.000 Zeilen
Y: analog zu X, nur eben eine Spalte (abhängige Variable)
2. keine Skalierung gewählt – mit Skalierung macht auch keinen Unterschied.
min_max_scaler = preprocessing.MinMaxScaler()
X_scale = min_max_scaler.fit_transform(X)
3. Ebenfalls problemlos Teilung in Trainings-, Validierungs- und Testdaten
X_train, X_test, Y_train, Y_test = train_test_split(X_scale, Y, test_size=0.2)
X_val, X_test, Y_val, Y_test = train_test_split(X_test, Y_test, test_size=0.5)
4. Mit diesem Code wird der Lauf angestoßen, aber in der Accuracy tut sich rein gar nichts…
model = Sequential()
model.add(Dense(32, activation=’relu‘, input_shape=(3,)))
model.add(Dense(32, activation=’relu‘))
model.add(Dense(1,activation=“relu“))
model.compile(optimizer=“sgd“, loss=“mean_squared_error“, metrics=[‚accuracy‘])
hist=model.fit(X_train,Y_train,batch_size=2,epochs=15, validation_data=(X_val,Y_val))
scores=model.evaluate(X_test, Y_test)
print(„Baseline accuracy: {:.2f}“.format(scores[1]*100))