

Nachrichten-Mining Teil 1: Die News API
Willst du Nachrichten im großen Stil analysieren? Willst du wissen, welche Stichwörter aktuell besonders oft in nationalen und internationalen Schlagzeilen zu finden sind? Kein Problem mit der API von newsapi.org. Wie du sie benutzt, erfährst du in diesem Beitrag.
Zugriff auf Nachrichten mit der News API
Mit der Schnittstelle von newsapi.org kannst du Schlagzeilen aus aller Welt ganz einfach in deine herunter laden. Bis zu 1.000 Requests am Tag sind kostenlos möglich. Wenn das Geld bei dir locker sitzt, kannst du auch für 449$ im Monat (Stand Mai 2018) bis zu 250.000 mal die Schnittstelle ansprechen. Allerdings brauchst du auch für die kostenlose Variante einen API Key. Dafür musst du einfach auf der Seite einen Account einrichten und schon kannst du den Key immer wieder benutzen.
Umsetzung in Python
Das Ziel soll es sein, die Daten mit der API in die Programmierumgebung zu laden und in ein Format zu bringen, mit dem man sie möglichst einfach auswerten kann. In unserem Fall ist dieses Format ein Pandas DataFrame.
Erst mal importieren wir die benötigten Module. Pandas brauchen wir als Modul für Datenstrukturen. Hiermit können wir Daten manipulieren und analysieren. Das Requests Package benötigen wir für die Kommunikation mit der Schnittstelle.
import pandas as pd import requests
Als nächstes weisen wir das Ergebnis des API Calls der Variable results zu. In der URL kopieren wir hinter das Argument apiKey unseren privaten Schlüssel für die Schnittstelle.
results = requests.get("https://newsapi.org/v2/sources?apiKey=MEIN_KEY")
Im JSON-Format sieht das Objekt results dann so aus.

Im obigen Ausschnitt siehst du die ersten 3 Nachrichtenquellen mit zusätzlichen Informationen wie Land, Sprache und Kategorie. Jetzt iterieren wir über das gesamte Objekt und schreiben alle Nachrichtenquellen in die Liste mit dem Namen sources. So sehen wir, welche Seiten uns für eine Analyse zur Verfügung stehen.
sources = []
for source in results.json()["sources"]:
sources.append(source["id"])
Die Liste umfasst 138 Einträge. Unten siehst du alle Medien, bei denen wir auf aktuelle Schlagzeilen zugreifen können. Deutsche Medien sind grün markiert.
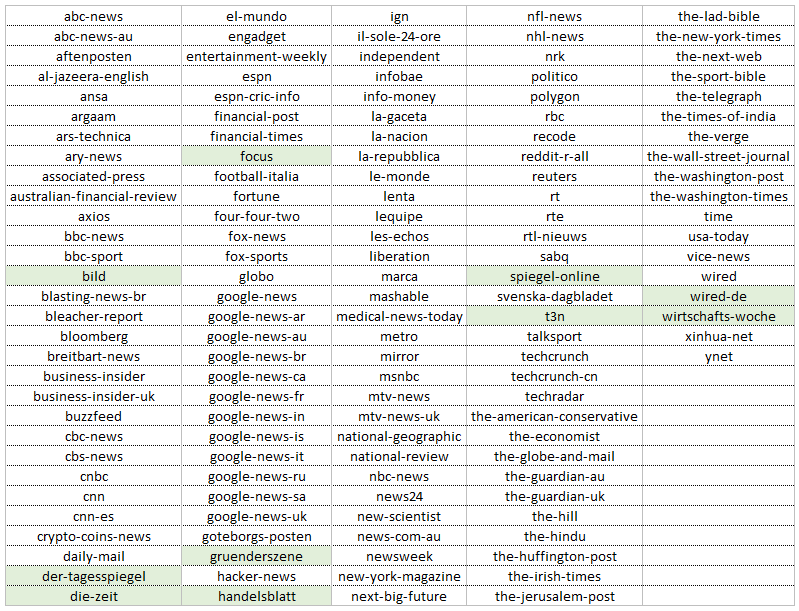
Unter den Quellen befinden sich also auch 10 deutsche Seiten mit zum Teil sehr hoher Reichweite.
Top News von Spiegel Online abrufen
Die Namen, welche du oben in der Tabelle siehst, können wir nun benutzen, um mit einem einem weiteren Link zur API die aktuellen Schlagzeilen der jeweiligen Zeitung abzurufen. Die Kennzeichnung „top-headlines“ innerhalb der URL bedeutet, dass wir die (meist 10) aktuellsten Schlagzeilen herunter laden.
headlines = requests.get("https://newsapi.org/v2/top-headlines?sources=spiegel-online&apiKey=MEIN_KEY").json()
print(headlines.keys())
print(headlines["status"])
print(headlines["totalResults"])

Soeben haben wir erfolgreich 10 aktuelle Nachrichten von Spiegel Online heruntergeladen. Durch die Funktion json wandeln wir beim API Call die Daten direkt in ein Dictionary um. Im Key namens articles befinden sich alle heruntergeladenen Schlagzeilen inklusive zusätzlicher Informationen. Die Schlagzeilen befinden sich wiederum in einer Liste aus Dictionaries. Schauen wir uns mal das erste Element an.
for i in headlines["articles"][0]:
print(str(i)+": "+str(headlines["articles"][0][i]))
print("")

Mit den obigen Informationen können wir also sagen, welche Schlagzeile zu welcher Zeit von welchem Medium veröffentlicht wurde – sogar mit Zeitstempel. Um nicht nur eine, sondern alle abgerufenen Nachrichten besser analysierbar zu machen, schreiben wir die 10 Schlagzeilen in einen DataFrame. Dafür erstellen wir pro Merkmal eine Liste, die für jeden Artikel entsprechend ausgefüllt wird.
ID=[]
name=[]
author=[]
title=[]
description=[]
url=[]
image_url=[]
timestamp=[]
for i in headlines["articles"]:
ID.append(i["source"]["id"])
name.append(i["source"]["name"])
author.append(i["author"])
title.append(i["title"])
description.append(i["description"])
url.append(i["url"])
image_url.append(i["urlToImage"])
timestamp.append(i["publishedAt"])
Die eben erstellten Listen können wir jetzt im DataFrame df_news speichern.
df_news = pd.DataFrame({"ID":ID,
"name":name,
"author":author,
"title":title,
"description":description,
"url":url,
"image_url":image_url,
"timestamp":timestamp})
df_news

Sieht gut aus! Jetzt haben wir die Daten geordnet vorliegen und können die Nachrichten analysieren.
Top News aller Nachrichtenquellen abrufen
Um aktuelle Nachrichten aller von der API bereit gestellten Quellen herunter zu laden, müssen wir unsere Abfrage leicht abändern. Dabei iterieren wir über die Liste sources, in der noch alle Medien gespeichert sind, und laden nach und nach die Top News aller Zeitungen in die Liste headlines.
headlines = []
for source in sources:
headlines.append(requests.get("https://newsapi.org/v2/top-headlines?sources={}&apiKey=MEIN_KEY".format(source)).json())
Das nun recht verschachtelte Objekt headlines besteht aus 138 Nachrichtenquellen, wobei in jeder Quelle meist 10 aktuelle Schlagzeilen stecken. Dieses Objekt schreiben wir jetzt wieder geordnet in einen DataFrame.
ID=[]
name=[]
author=[]
title=[]
description=[]
url=[]
image_url=[]
timestamp=[]
for i in range(len(headlines)):
try:
for k in headlines[i]["articles"]:
ID.append(k["source"]["id"])
name.append(k["source"]["name"])
author.append(k["author"])
title.append(k["title"])
description.append(k["description"])
url.append(k["url"])
image_url.append(k["urlToImage"])
timestamp.append(k["publishedAt"])
except Exception as e:
print(e)
df_news = pd.DataFrame({"ID":ID,
"name":name,
"author":author,
"title":title,
"description":description,
"url":url,
"image_url":image_url,
"timestamp":timestamp})
df_news.head()

Auch das sieht gut aus! Den try-Befehl habe ich eingebaut, weil manchmal die eine oder andere Quelle nicht erreichbar ist – meistens klappt jedoch alles. Schauen wir mal, wie viele Artikel pro Nachrichtenquelle abgerufen wurden.
df_news.ID.value_counts().value_counts()

In 113 von 138 Fällen wurden von den jeweiligen Medien 10 News herunter geladen. Insgesamt ist der neue DataFrame 1273 Zeilen lang, so viele Schlagzeilen haben wir also insgesamt abgerufen. Bei großen Datenmengen musst du darauf achten, dass du maximal 1.000 Requests am Tag an die API schicken kannst.
Als Beispiel können wir mit den gesammelten Daten zum Beispiel untersuchen, wie oft US-Präsident Donald Trump im Moment in den Nachrichten ist. Dafür schauen wir einfach in den Kurzbeschreibungen der Schlagzeilen nach dem Stichwort „Trump“ und summieren die Zahl der Treffer pro Herausgeber. Gucken wir uns mal die Top 10 an.
grouped = df_news.groupby("ID").agg({"Trump":[sum]})
grouped.sort_values(by=[("Trump","sum")],ascending=False).iloc[:10]

Der US-Präsident hat es heute also schon in 6 verschiedene Schlagzeilen der Zeitung „The Hill“ geschafft.
So einfach kannst du die aktuellen Schlagzeilen aus aller Welt herunter laden und so formatieren, dass du sie sinnvoll analysieren kannst. Doch das sind nicht alle Möglichkeiten der News API. Wie du nicht nur die aktuellsten News, sondern alle Schlagzeilen innerhalb eines bestimmten Zeitraums abrufst oder direkt beim API Call nach Stichwörtern filterst, erfährst du im nächsten Beitrag. Bis dahin viel Spaß beim Nachmachen!
Hinweis: Du veröffentlichst in „Top News aller Nachrichtenquellen abrufen“ deinen API-Key 😉
Vielen Dank für den Hinweis! 🙂