

Python: Daten gruppieren und aggregieren mit Pandas (Vertiefung)
Daten gruppieren und aggregieren ohne Grenzen. Benutze eigene Funktionen und aggregiere dieselben Metriken mit verschiedensten Methoden.
Rückblick und Vorschau
Im letzten Beitrag ging es um die Grundlagen der Gruppierung von Daten in Python. Genauer gesagt haben wir in einer Stichprobe die Daten nach bestimmten Eigenschaften gruppiert und im selben Abwasch für diese Gruppen deskriptive Statistiken erstellt. Für den Anfang ganz nett. Und sehr oft genügt diese Methode, um die eigenen Fragen zu beantworten. Doch manchmal will man noch ein bisschen mehr aus den Daten herauskitzeln als nur Durchschnitte. Als Beispiel nehmen wir wieder Daten vom deutschen Immobilienmarkt. Damit die Analyse etwas spannender wird, nehmen wir allerdings den kompletten Datensatz, den ich hier geminet habe. Also können wir nicht nur 20, sondern 52.000 Wohnungen statistisch auseinander nehmen. Dazu laden wir unsere Daten wieder in einen Pandas DataFrame und benennen die Spalten sinnvoll.
wohnungen = df[["URL","geo_bln","geo_krs",
"geo_plz","obj_balcony","obj_barrierFree",
"obj_baseRent","obj_cellar","obj_floor",
"obj_garden","obj_hasKitchen","obj_livingSpace",
"obj_noRooms","obj_numberOfFloors",
"obj_telekomDownloadSpeed","obj_yearConstructed",
"obj_typeOfFlat","obj_interiorQual"]]
spaltennamen = ["URL","bundesland","stadt","plz",
"hat_balkon","barrierefrei","kaltmiete",
"keller","etage","garten","hat_kueche",
"wohnflaeche","zimmer","anzahl_etagen",
"internet","baujahr","wohnungstyp","interieur"]
wohnungen.columns = spaltennamen
print(wohnungen.columns)

Spalten mit unterschiedlichen Methoden aggregieren
Im letzten Beitrag haben wir eine Aggregierungsfunktion auf alle Spalten angewendet – und zwar mean(). Doch was ist, wenn ich zum Beispiel den Durchschnitt der Kaltmiete und die Anzahl der Wohnungen in der jeweiligen Gruppe gleichzeitig berechnen will? Dafür gibt es die mit groupby() verkettete Funktion agg(). Wenn wir also die genannte Statistik pro Bundesland berechnen wollen, machen wir folgendes:
gruppiert = wohnungen.groupby("bundesland").agg({
"kaltmiete":["mean"],
"URL":["count"]})
gruppiert
Als Argumente weisen wir der Funktion agg() ein Dictionary zu, welches die relevanten Spalten zusammen mit den Aggregierungsmethoden enthält. Warum diese Methoden wiederum in Listen sind, siehst du später. Heraus kommt diese Tabelle:

Die Tabelle enthält alle Bundesländer als Index, die durchschnittliche Kaltmiete als erste Spalte und die Anzahl der Wohnungen im jeweiligen Bundesland als zweite Spalte (URL fungiert hier als eindeutige Wohnungs-ID). Was im Allgemeinen sinnvoll ist, mich für die weitere Bearbeitung aber meist stört, ist der mehrzeilige Index der Spalten. Dieser macht es umständlicher, mit den neuen Spalten Berechnungen durchzuführen, weil man die Spalten immer mit beiden Indexzeilen ansprechen muss. Deshalb ersetze ich meistens die gesamten Spaltenköpfe durch ihre jeweils erste Zeile.
gruppiert.columns = gruppiert.columns.get_level_values(0)

Das sieht schon besser aus. So einfach können wir für unterschiedliche Spalten unterschiedliche Methoden zur Aggregierung definieren.
Dieselbe Spalte mit unterschiedlichen Methoden aggregieren
Manchmal reicht es uns nicht, nur eine zusammenfassende Statistik pro Dimension zu haben. Was machen wir, wenn wir nicht nur den einfachen Durchschnitt, sondern auch den Median für die Kaltmiete berechnen wollen? Genau deshalb sind die Aggregierungsmethoden im Dictionary der Funktion agg() in Listen eingebettet. Dort können wir nämklich die Funktionen, mit denen wir rechnen wollen, auflisten.
gruppiert = wohnungen.groupby("bundesland").agg({
"kaltmiete":["mean","median"]})
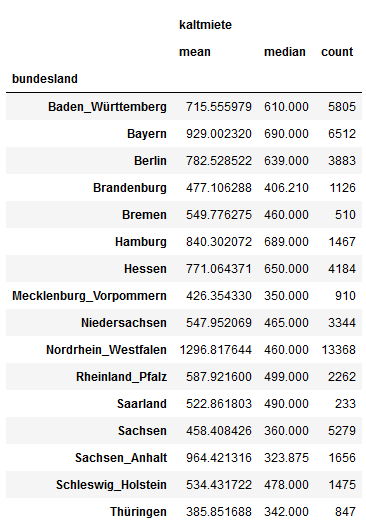
Jetzt haben wir eine Spalte nach Bundesländern gruppiert und mit den beiden Funktionen mean()undmedian()aggregiert. Auch in diesem Fall können wir die Spaltenköpfe umbenennen. Dieses Mal löschen wir die zweite Zeile der Spaltennamen aber nicht, sondern fassen beide Zeilen einfach zusammen. So erkennen wir auch, wie die Spaltenwerte berechnet wurden.
gruppiert.columns = gruppiert.columns.get_level_values(0)+"_"+gruppiert.columns.get_level_values(1)

Daten aggregieren mit eigenen Funktionen
Mit den Standardfunktionen von Pandas kommt man schon weit. Aber was tut man, wenn die Funktion, die man anwenden will, nicht dabei ist? Ganz einfach: Man wendet seine eigene Funktion an – und zwar mit dem Lambda-Operator. Mit diesem können wir jede beliebige Funktion auf ein groupby()-Objekt anwenden.
gruppiert = wohnungen.groupby("bundesland").agg({"kaltmiete":[lambda x: np.percentile(x,[75])]})
gruppiert

Das „x“ in „lambda x:“ bezieht sich auf die Spalte „kaltmiete“, die hier aggregiert werden soll. Dahinter kannst du jede beliebige Funktion mit „x“ als Argument anführen. So einfach ist das! In dem Fall oben habe ich die Funktion percentile() des Python-Moduls Numpy genommen. Diese berechnet hier folglich für jedes Bundesland das 75. Perzentil der Kaltmiete, wobei man natürlich jedes beliebige Perzentil berechnen kann. Drei Viertel aller Wohnungen in Hamburg kosten also 1.000€ oder weniger.
Und so einfach gruppierst und aggregierst du Daten in Python. 🙂
Super Erklärung
Obwohl ich schon einiges probiert habe
Habe ich jetzt erst die Bedeutung der agg Funktion so richtig verstanden
Daumen hoch!