
Lineare Regression und Anwendung in Python
Mit linearer Regression überprüfst du ganz einfach, ob es zwischen zwei Merkmalen einen linearen Zusammenhang gibt. Wie genau du das anstellst, erfährst du hier.
Ein einführendes Beispiel
Wenn du schon weißt, was lineare Regression ist, kannst diesen und den Theorieteil ignorieren und direkt zur Implementierung in Python springen. Allerdings wird das Beispiel auch dort benutzt.
Stell dir vor, du willst umziehen. Du bist gerade auf Wohnungssuche und weißt noch nicht, wie viel dich deine neue Wohnung kosten wird. Allerdings willst du nicht einfach in die Wohnung mit der geringsten Miete ziehen, sondern du hast Ansprüche – vor allem an die Wohnfläche. Mindestens 60 Quadratmeter sollten es sein. Doch wie viel musst du schätzungsweise für eine Wohnung in der Größe bezahlen? Um die Frage zu klären, siehst du dir im Internet einige Wohnungen samt Wohnfläche und Miete an. Dass größere Wohnungen tendenziell teurer als kleinere sind, weißt du schon aus Erfahrung. Um die Aussage zu überprüfen, zeichnest du die Miete und Quadratmeterzahl jeder Wohnung auf. Dabei siehst du folgendes.
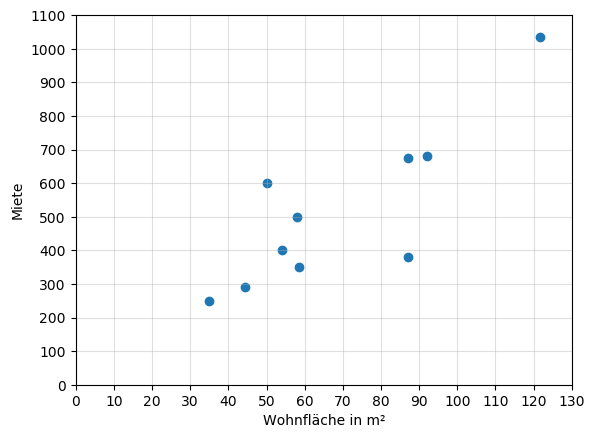
Das Bild stimmt mit deiner Erfahrung überein, es existiert – zumindest in deiner Stichprobe – ein positiver Zusammenhang zwischen Wohnfläche und Miete. Trotzdem ist die aus den Daten gewonnene Aussage ein wenig schwammig. Manche der Wohnungen kosten dasselbe, aber unterscheiden sich enorm in der Wohnfläche. Du willst eine einheitliche Regel finden, mit der du genau schätzen kannst, wie viel du für eine Wohnung mit 60m² ausgeben musst. Und genau dabei hilft dir lineare Regression.
Was ist lineare Regression?
Lineare Regression ist ein statistisches Verfahren, mit dessen Hilfe eine Gerade auf die Weise durch die Daten gelegt wird, dass sie die Daten am besten repräsentiert. Und das ist genau dann der Fall, wenn die Summe der quadrierten Abstände zwischen der Geraden und den Daten am kleinsten ist. Diese Methode zur Bestimmung der Gerade nennt man auch die Methode der kleinsten Quadrate. Mit diesem Schätzer erhältst du eine Funktion, mit deren Hilfe du für jeden Wert einer unabhängigen Variable (Wohnfläche) den Wert der abhängigen Variable (Miete) bestimmen kannst.
Die Gerade ist definiert durch die Gleichung ist y=a+b*x. Die Miete im Beispiel wird hier durch die Zielgröße y repräsentiert. Unser Ziel ist es, y für jede beliebige Quadratmeterzahl zu berechnen. Das tun wir mit Hilfe der unabhängigen Variable x, dem Achsenabschnitt a und dem Steigungskoeffizienten b. Was die unabhängige Variable ist, haben wir bereits geklärt. Der Achsenabschnitt ist der Wert von y, bei dem die Gerade die senkrechte Achse schneidet. In unserem Beispiel wäre das theoretisch die Miete, welche man für eine Wohnung mit 0 Quadratmetern zahlen müsste. Der Koeffizient b ist der Wert, mit dem die Zielgröße ansteigt, wenn man die unabhängige Variable mit 1 erhöht. Auf unser Beispiel bezogen: Wie viel mehr muss ich für eine Wohnung bezahlen, die einen Quadratmeter größer ist? Die genaue Herleitung der gesamten Geradengleichung kannst du bei crashkurs-statistik.de nachlesen.
Implementierung in Python
Um ein lineares Regressionsmodell in Python umzusetzen, brauchst du nur wenige Arbeitsschritte. Die Basis bildet die Funktion linregress des Python-Packages Scipy. Dieses Package bietet allerlei Werkzeuge für Statistik und ist unter anderem Bestandteil der Anaconda-Distribution. Solltest du noch nicht im Besitz von Scipy sein, kannst du hier nachschauen, wie du es installierst.
from scipy.stats import linregress
Scipy hat eine eigene Funktion für lineare Regressionsanalyse. Als Argumente weist man ihr jeweils einen Array der x– und der y-Werte zu. Neben Numpy-Arrays akzeptiert die Funktion auch Listen, Tupel und Pandas Series. Als Ergebnis erhalten wir dann die Steigung, den Achsenabschnitt, den Korrelationskoeffizienten nach Pearson (R), den p-Wert und die Standardabweichung. Die einzelnen Werte kann man in dieser Reihenfolge auch gleich beim Aufrufen der Funktion in separate Objekte entpacken. So kann man anschließend besser mit den Kennzahlen arbeiten.
b, a, r, p, std = linregress(wohnflaeche,miete)
Folgende Werte wurden von der Funktion ausgerechnet.
b = 7,37 a = 8,96 r = 0,83 p = 0,00 std = 1,72
Damit lautet unsere Geradengleichung:
y = 8,96 + 7,37 * x oder Miete = 8,96 + 7,37 * Wohnfläche
Was bedeuten die Werte für unser Beispiel? Ein Wert von 8,96 für den Achsenabschnitt bedeutet, dass laut dem Modell eine Wohnung mit 0 Quadratmetern Wohnfläche 8,96€ im Monat kostet und mit jedem Quadratmeter 7,37€ teurer wird. Mit der Wohnfläche steigt die geschätzte Miete linear an, deshalb auch lineare Regression. Jetzt können wir ausrechnen, wie viel wir für eine 60m² große Wohnung zahlen müssen – und zwar 451,16€. Die Regressionsgerade lässt sich auch ganz einfach zusammen mit dem oben gezeigten Streudiagramm darstellen.
plt.scatter(wohnflaeche, miete)
plt.plot([0,130],[a,a+130*b],c="red",alpha=0.5)
plt.plot()
plt.xlim(0,130)
plt.ylim(0,1100)
plt.xlabel("Wohnfläche in m²")
plt.ylabel("Miete")
plt.grid(alpha=0.4)
plt.xticks([x for x in range(131) if x%10==0])
plt.yticks([x for x in range(1101) if x%100==0])
plt.show()
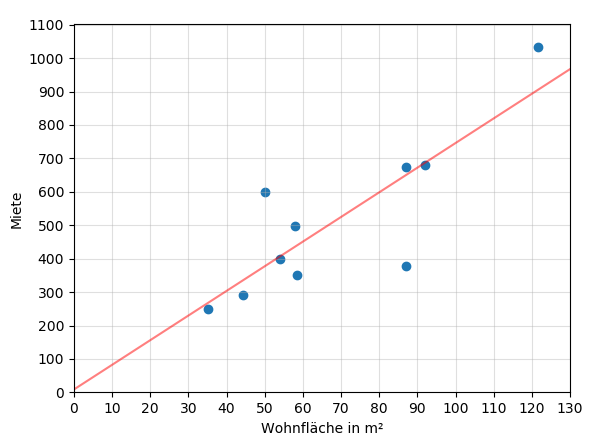
Natürlich ist es nur in einem gewissen Rahmen sinnvoll, die Miete in Abhängigkeit von der Wohnfläche zu schätzen. In der Realität wirst du wohl kaum 10m² große Wohnungen finden. Doch für den Bereich, in dem uns Daten vorliegen, scheint die lineare Regression eine recht gute Annäherung zu sein.
Vor- und Nachteile von linearer Regression
In der Gesamtmenge von statistischen Modellen und Machine-Learning-Algorithmen gehört lineare Regression zu den Basics. Die Methode ist leicht zu verstehen und einfach zu interpretieren. Vor allem bei großen Datenmengen kommt der Vorteil hinzu, dass diese Methode im Vergleich zu anderen Verfahren einem Computer relativ wenig Rechenleistung abverlangt. Am anderen Ende des Spektrums haben wir beispielsweise neuronale Netze, die – abhängig von der Komplexität und Datenmenge – mehrere Tage brauchen können, bis sie sich an die Daten „optimal“ angepasst haben.
Der Nachteil linearer Regressionsmodelle ist, dass sie oft ungenauer sind als komplexere Methoden. Zwar wird auch heute noch oft lineare Regression eingesetzt (aus den oben genannten Gründen), in vielen praktischen Anwendungen wird heutzutage jedoch auf andere Verfahren zurückgegriffen. Hauptgrund für die Entwicklung hin zu komplexeren Modellen ist die enorm gewachsene Rechenleistung in den letzten 10 Jahren und die damit verbundenen geringeren Kosten für rechenintensive Verfahren.
Hallo,
hier ist wieder der Pythonanfänger. Ich habe Deine Tutorials nachgemacht und mich aber für die polynomiale Regression entschieden. Gründe hierfür sind:
* Lineare regression ist nur ein Sonderfall der poly. Regression mit Potenz 1. Oder habe ich das falsch verstanden?
* Bei 11 inputvariablen (fläche, Baujahr, Zustand, etc.) und der Outputvariable (Hauspreis) weiss ich ja nicht a priori ob es einen linearen Zusammenhang gibt. Deshalb habe gehe ich auf poly. Regr.
Wie schätzt Du meine Gedankengänge ein? Macht das so Sinn oder sind das falsche Annahmen?
Ich habe noch ein sehr grosses Problem, nämlich die Lage, die ich über die Postleitzahl abreife. Die PLZ ist ja eine nominale Grösse, der Regressionsalgorithmus behandelt es aber als Float und damit als metrische Grösse. Dadurch sollte der Algorithmus ja annehmen, je grösser die PLZ, desto höher der Mietpreis. Aber das entspricht ja überhaupt nicht der Realität. Denn Berlin mit 1er PLZ ist teuer, oder Frankfurt oder München.
Hast Du hier einen Tipp, wie man die Lage berücksichtigen
Danke
Pythonanfänger
Hi Pythonanfänger,
cool, dass du mal wieder vorbei schaust!
zur polynomialen Regression:
Du hast recht. Man weiß im Voraus nicht, wie der Zusammenhang zwischen den Daten ist. In den seltensten Fällen wird er exakt linear sein. Mit einem Polynom höheren Grades kannst du unter Umständen eine bessere Repräsentation deiner Daten durch deine Regressionsfunktion erreichen. Diese ist nur etwas schwerer umzusetzen und zu interpretieren, weil der Einfluss von X auf Y von der Lage von X abhängt (ein Änderung von X=10 auf X=11 wirkt sich laut Polynom vielleicht positiv auf Y aus, eine Änderung von X=100 auf X=101 aber negativ).
Wie sehr deine Daten linear zusammenhängen, kannst du mit dem Korrelationskoeffizienten „R“ prüfen.
Noch ein Praxistipp:
Sagen wir, dein Y hängt nicht linear, sondern quadratisch von der Variable X1 ab. Es verdoppelt sich mit jeder Einheit, um die X1 erhöht wird.
Was du dann statt einer polynomialen Regression machen kannst, ist, eine neue Variable X2 = X1^2 zu definieren, von der Y wiederum linear abhängt.
Du kannst also, statt mit Originalvariablen Polynome zu bauen, Variablen transformieren und diese in dein lineares Modell einfließen lassen.
In der Praxis wird bei Regressionsanalysen oft gesagt, dass zum Beispiel das logarithmierte Gehalt linear von der Berufserfahrung abhängt etc. Hier wurde zum Beispiel Y so transformiert, dass es sich mit einem linearen Modell schätzen lässt.
Nun zu den Postleitzahlen bzw. Auswirkungen der Lage eines Hauses:
Wie du schon erkannt hast, ist die PLZ eine nominale Größe. Was mir spontan einfällt: Du könntest für jede PLZ den Längen- und Breitengrad bestimmen.
So kannst du untersuchen, ob Häuser in Süddeutschland teurer sind als in Norddeutschland. Schau mal hier vorbei. Dort gibt es Tabellen mit allen Orten, Postleitzahlen und dazu gehörigen Koordinaten in Deutschland. Genauer kannst du dir hier die Datei „DE.tab“ runter laden. Ist eine Tab-separierte Datei, die sich mit Pandas leicht in Python einspielen lässt. Falls du dazu Fragen hast, sag bescheid.
Ansonsten könntest du dir noch Informationen über die Einwohnerzahlen holen und diese in dein Modell einfließen lassen. Zum Beispiel die Einwohnerzahl an sich als metrische Variable oder abhängig von Ort und Einwohnerzahl die Variable „Stadt: ja / nein“. Nach dem Motto „wo mehr Menschen wohnen, sind Häuser tendenziell teurer“.
Ich hoffe, ich konnte dir damit weiter helfen! 🙂
Chris
Hallo,
eine Frage zur Regression bleibt mir noch.
Bei uns im Praktikum wird viel mit Linearer Regression ausgewertet und wir nutzen die Polyfit Variante. Ich würde mir nun gerne die Daten printen lassen die die Funktion berechnet um den Ordinatenabschnitt bestimmen zu können, gibt es dafür einen extra Befehl, bin bis dato nicht fündig geworden.
Liebe Grüße aus der Medizinphysik
Vera
Hi Vera,
für die Polyfit-Funktion von Numpy (die meinst du doch?) habe ich folgende Lösung:
Sagen wir, du hast zwei Listen X und y und willst die Regressionslinie für y in Abhängigkeit von X plotten.
import numpy as np
import matplotlib.pyplot
X = [1,2,3,4]
y = [3,5,7,10]
polyfit = np.polyfit(X,y,deg=1)schaetzer = np.poly1d(polyfit)
plt.scatter(X,y)plt.plot(X, schaetzer(X),color="red",alpha=0.5)
plt.xlim(0, 5)
plt.ylim(0, 12)
plt.show()
Die Variable „schaetzer“ ist eine Funktion, die für jedes X das y schätzt. Der Funktion kannst auch deine Liste an X-Werten übergeben. Das Ergebnis des ganzen ist dann ein Scatterplot mit den Rohdaten und als Overlay eine Regressionsgerade.
Ich hoffe, die Antwort hilft dir weiter! 🙂
Hallo,
ich habe momentan mein physikalisches Praktikum und muss dafür Dateb auswerten und eine lineare Regression durchführen. Dabei bin ich auf diese Seite gestoße, die mir auch weitergeholfen hat.
Ich hätte da aber noch eine Frage und zwar verstehe ich nicht wo die 130 in a+b*130 in dder Zeile 2 herkommt:
plt.plot([0,130],[a,a+130*b],c=“red“,alpha=0.5.
Je nachdem was man statt 130 einsetzt kommt eine andere Gerade raus. Woher weiß ich welche die gesuchte gerade ist?
Über eine Antwort würde ich mich sehr freuen.
LG
Ishmeet Vohra