
Logistische Regression als Machine Learning Algorithmus in Python
In diesem Tutorial geht es um das logistische Regressionsmodell als Machine Learning Algorithmus. Hier erfährst du zum einen die Theorie und bekommst zum anderen eine Schritt-für-Schritt-Anleitung darüber, wie du logistische Regression in Python anwendest.
(Wenn du nur den Python-Code zum Algorithmus sehen willst, dann scrolle einfach bis zum 2. Kapitel)
1. Was ist logistische Regression
Logistische Regression ist ein statistisches Verfahren, mit dem der Wert einer Zielvariable in Abhängigkeit von einer oder mehreren unabhängigen Variablen geschätzt wird. Der Unterschied zum linearen Modell besteht darin, dass Y – also die Zielvariable – binär ist. Das heißt, dass das wahre Y zwei mögliche Ausprägungen haben kann. Meistens findet man die Werte 1 (Erfolg, ja, positiv etc.) und 0 (nein, kein Erfolg, negativ etc.). Analysten und Data Scientists nutzen die logistische Regression deshalb so oft für binäre Prognosen, weil das Ergebnis der Regressionsfunktion nur Werte im Intervall [0,1] annehmen kann. Die Funktionsgleichung sieht wie folgt aus:

An der Gleichung siehst du, dass nicht direkt der Wert für Y berechnet wird. Viel mehr schätzt das Modell die Wahrscheinlichkeit dafür, dass der wahre Wert von Y gleich 1 ist. In der Potenz der e-Funktionen ist das „normale“ lineare Modell verbaut. Allerdings wurde es so transformiert, dass die Gleichung nur Werte zwischen 0 und 1 ausgeben kann. Das verdeutlicht auch der unten stehende Graph, welcher die Funktion f(x)=(e^x/(1+e^x)) zeigt.
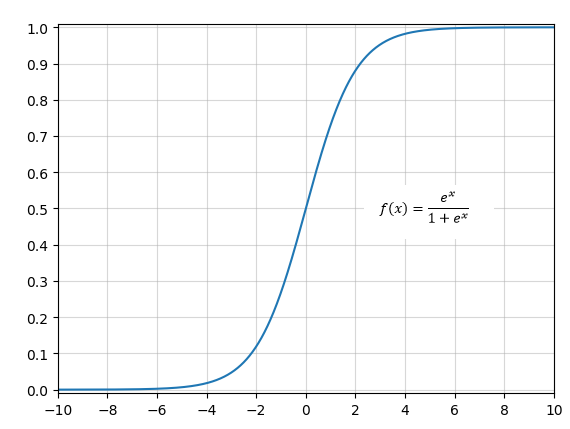
Egal, was du für x einsetzt, es kommen immer Werte zwischen 0 und 1 heraus. Ein unverändertes lineares Modell würde der Schätzung von binären Zielwerten nicht gerecht werden, weil dann theoretisch auch Wahrscheinlichkeiten kleiner 0 oder größer 1 möglich wären.
Falls du noch tiefer in die Theorie des logistischen Regressionsmodells einsteigen willst, dann findest du in diesem Artikel der Hochschule Luzern noch mehr dazu.
Praktische Beispiele
Die logistische Regression ist ein geeignetes Verfahren für Risikoanalysten in der Bankenbranche. Mit dem Modell kann man die Wahrscheinlichkeit schätzen, zu der ein Kreditnehmer zahlungsunfähig wird und somit der Kredit ausfällt. Im Marketing kann man zum Beispiel abschätzen, ob ein Kunde mit bestimmten Eigenschaften ein Produkt kaufen wird oder nicht. Im Gesundheitssektor könnte man mit Hilfe logistischer Regression die Wahrscheinlichkeit des Auftretens von gewissen Krankheiten bei Patienten mit bestimmten biometrischen Werten voraussagen.
2. Logistische Regression in Python
Als Beispiel nehmen wir einen Ausschnitt der Daten aus dieser Beitragsreihe, welche Eigenschaften von rund 52.000 neu vermieteten Wohnungen in Deutschland enthalten. Die Tabelle besteht sowohl aus metrischen (Kaltmiete, Baujahr etc.), als auch aus binären (Küche vorhanden, Wohnung ist barrierefrei etc.) Daten. Mit Hilfe dieser Eigenschaften werden wir vorhersagen, ob sich eine Wohnung in einem Haus mit oder ohne Fahrstuhl befindet. Schauen wir uns mal ein Sample der Daten an, welche sich in einem Pandas DataFrame befinden.
data.sample(10)


Das sind unsere Rohdaten – insgesamt 17 Spalten und genau 52.861 Zeilen. Wie du siehst, sind die Daten nicht perfekt. Ein möglicher Grund für Unsauberkeiten kann sein, dass diese Felder der von immobilienscout24 stammenden Daten keine Pflichtfelder sind. Wenn du wissen willst, wie man Rohdaten in Python grundlegend säubert, dann kannst du es in diesem Tutorial nachlesen.
Um logistische Regression sinnvoll in Python umzusetzen, bedienen wir uns bei scikit-learn. Dieses Paket beinhaltet viele verschiedene Werkzeuge für statistische Modelle wie lineare und logistische Regression, Entscheidungsbäume, Random Forests, kNN und so weiter.
Module importieren
Als erstes importieren wir das Modell selbst.
from sklearn.linear_model import LogisticRegression
Außerdem brauchen wir eine Funktion, welche die Rohdaten in Trainings- und Testdaten teilt. Auf die Trainingsdaten schmeißen wir das Modell, welches sich an diese anpasst und versucht, einen möglichst genauen Schätzer zu bauen.
from sklearn.model_selection import train_test_split
Die Variablen
Jetzt haben wir alles importiert, was wir benötigen. Der nächste Schritt ist, die Variablen zu initiieren.
X = data.fillna(-1).drop("Aufzug_vorhanden",axis=1).values
Weil wir nicht nur eine, sondern 16 erklärende Variablen haben, ist X nicht nur eine Datenreihe, sondern eine Matrix mit den Dimensionen 52.861 mal 16. Dazu hat Pandas die Methode .values, welche aus einem DataFrame eine Matrix macht (Spaltennamen fallen also weg). Außerdem kann das logistische Modell, wie viele andere Machine-Learning-Algorithmen auch, nichts mit leeren (NaN) Einträgen anfangen. Deshalb müssen wir diese ersetzen. Hier gibt es keinen allgemein richtigen Wert, der immer gute Ergebnisse liefert. Der Einfachheit halber ersetzen wir die leeren Einträge mit „-1“. Außerdem müssen wir natürlich die Spalte „Aufzug_vorhanden“ entfernen. Es ist mir schon passiert, dass ich die Spalte nicht entfernt habe und nach dem ersten Durchlauf ein fast perfektes Modell hatte. Das passiert, wenn die Variable, die man eigentlich schätzen will, schon für die Modellerstellung genutzt wird. Um eine Spalte aus einem DataFrame zu entfernen, gibt es die Methode .drop. Hierbei musst du auch immer angeben, ob du eine Spalte (axis=1) oder eine Zeile (axis=0) löschen willst.
Als nächstes initiieren wir die Zielvariable.
y = data.fillna(-1)["Aufzug_vorhanden"].values
Hier wollen wir einen Array mit ausschließlich der zu schätzenden Variable haben. Checken wir zur Kontrolle noch mal die Dimensionen von X und y.
print(X.shape) print(y.shape)
![]()
Sieht gut aus. Dann können wir die Daten jetzt in Trainings- und Testdaten splitten.
Train-Test-Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
Die Funktion train_test_split() spaltet die Daten in zwei separate Kategorien: Testdaten und Trainingsdaten. Mit den Trainingsdaten wird der Algorithmus versuchen, einen optimalen Schätzer zu bauen. Dabei iteriert er immer wieder über die Daten, vergleicht seine Schätzung von y mit dem wahren y der Trainingsdaten, passt die Schätzfunktion an und verbessert sie in dieser Weise Schritt für Schritt. Wenn das Modell den bestmöglichen Schätzer erstellt hat, wird zum Schluss die Güte dieses Schätzers anhand der Testdaten gemessen. Das Ziel von Machine Learning ist es ja, aufgrund bekannter Daten Aussagen über neue, vorher unbekannte Daten treffen zu können. Hier sind die Trainingsdaten das, was uns bekannt ist und die Testdaten sind das neue Unbekannte. Die Funktion train_test_split() nimmt als Argumente (unter anderem) X und y sowie die Größe der Testdaten. In diesem Beispiel nutzen wir 80% der Daten zum Trainieren des Modells und testen das Modell mit den restlichen 20%. Die Funktion wählt die Daten zufällig. Das heißt auch, dass die Performance des Modells von Durchgang zu Durchgang schwanken kann, denn Abweichungen in der Zusammensetzung der Daten wirken sich auf die Präzision des Schätzers aus. Schauen wir uns auch hier noch mal die Dimensionen der erstellten Objekte an.
print("X_train: " + str(X_train.shape))
print("y_train: " + str(y_train.shape))
print("X_test: " + str(X_test.shape))
print("y_test: " + str(y_test.shape))

Auch das sieht gut aus. Dann können wir jetzt das Modell initiieren und es auf die Trainingsdaten anwenden.
Das Modell trainieren
logreg = LogisticRegression() logreg.fit(X_train,y_train)
Der fit-Befehl ist einer der zentralen Befehle im Machine Learning. Hier geschieht das Lernen – der Algorithmus versucht, anhand der ihm zur Verfügung gestellten Rohdaten einen Schätzer zu bauen, welcher mit dem kleinstmöglichen Fehler den wahren Wert der Zielvariable vorhersagt. Es ist dieser Befehl, der Machine Learning so rechen- und damit zeitaufwendig macht. In unserem Beispiel braucht das logistische Modell ca. 0,25 Sekunden, um einen Schätzer zu bauen. Das ist vergleichsweise wenig, jedoch arbeiten wir auch mit einem sehr kleinen Datensatz und einem wenig rechenintensiven Algorithmus. Bei Datensätzen mit mehreren hundert erklärenden Variablen und einigen Millionen Zeilen können auch logistische Modelle eine Stunde oder sogar länger brauchen, um eine Schätzfunktion zu erstellen.
Das Modell testen
Das Modell ist fertig trainiert. Was heißt das? Das heißt, wir können mit diesem Modell nun für beliebig viele neue Daten den Wert der Zielvariablen vorhersagen. Die neuen Daten müssen natürlich dieselben Spalten wie die Trainingsdaten besitzen.
Jetzt testen wir das Modell, indem wir ihm die neuen Daten vorsetzen. Der folgende Befehl nimmt die Testdaten und generiert einen Array mit Schätzwerten für y.
y_pred = logreg.predict(X_test)
Wir haben nun die Möglichkeit, den Array der Schätzwerte mit dem der wahren Werte zu vergleichen. Grundsätzlich kann man sagen: Je mehr Werte übereinstimmen, desto besser das Modell. Wir stellen also den geschätzten Array dem wahren Array gegenüber und schauen uns an, wie hoch der Prozentsatz der Fälle ist, in denen das Modell richtig liegt.
print("Accuracy Score: " + str(logreg.score(X_test,y_test)))
![]()
Unser logistisches Regressionsmodell liegt in rund 85% der Fälle richtig. In 17 von 20 Fällen erkennt der Algorithmus richtig, ob die Wohnung in einem Haus mit Fahrstuhl liegt oder nicht. Ist das gut oder schlecht? Die Antwort lautet: Es kommt drauf an.
Bitte anpassen, zuerst war die Rede von einer Schätzung von der Verfügbarkeit eines Fahrstuhls und anschließend wurde aufeinmal auf die Verfügbarkeit eines Balkons evaluiert.
Hi Ali,
danke für die Korrektur!
Grüße
Chris