

ImmobilienScout24 Mining Teil 3: Datensäuberung in Python
Es ist vollbracht!
Der Scraper hat fertig. Nach einem knappen Monat hat mein Web Scraper genau 27.454-mal ImmobilienScout24 besucht und die 20 aktuellsten Wohnungsangebote heruntergeladen. Mehrere Stunden hat mein PC gebraucht, um die Dateien zusammenzusetzen. Heraus kam eine 1,5 GB große CSV-Datei mit 550.000 Zeilen. Auch für eine Tabelle dieser Dimension ist die Datei sehr groß. Dafür verantwortlich ist wahrscheinlich die Spalte, in der sich zu jedem Wohnungsangebot der komplette Fließtext befindet. Wie im letzten Artikel schon erwähnt sind die meisten Zeilen in der Tabelle Duplikate, die es erst mal zu löschen gilt. Bleiben gut 52.000 eindeutige Wohnungen übrig, also waren über 90% der Daten Duplikate. Das ursprüngliche Ziel war eine doppelt so große Datenbasis, jedoch ist mein alter Laptop nicht mehr dazu bereit, mehrere Tage durchgängig zu arbeiten, ohne sich aufzuhängen. Doch auch mit 52.000 Wohnungen können wir ausgezeichnet arbeiten.
Erst die Arbeit, dann das Vergnügen
Im letzten Teil der Artikelreihe hatte ich ja versprochen, dass wir uns jetzt mit der Analyse der Daten beschäftigen werden. Ziemlich optimistisch. Natürlich sind die Daten nicht sauber, viele der eigentlich numerischen Spalten haben entweder das komplett falsche oder mindestens ein gemischtes Datenformat. Also lasst erst uns mal ein wenig Datensäuberung betreiben.
Die Datensäuberung
Als erstes wird Pandas importiert.
import pandas as pd
Dann laden wir die Daten in die Programmierumgebung von Python.
df = pd.read_csv("MeinPfas/MeineDaten.csv",sep=";")
In der Funktion .read_csv() müssen zusätzlich zum Dateipfad noch angeben, dass ein Semikolon als Spaltentrenner fungiert. Ohne diese Angabe würde Pandas das Komma benutzen und einen Lesefehler ausgeben.
Als allererstes nach dem importieren der Daten gucke ich mir immer die ersten 5 Zeilen an.
df.head()
Die folgenden beiden Screenshots sind nur Ausschnitte der kompletten Tabelle mit allen Spalten. Wie die Dimensionen tatsächlich aussehen, finden wir gleich heraus.


Die Funktion .head() gibt standardmäßig die ersten 5 Zeilen zurück. Allerdings kann man der Funktion auch als Argument die gewünschte Zahl der Zeilen zuweisen (zwischen die Klammern schreiben). Analog zu .head() gibt .tail() die letzten Zeilen eines Dataframes zurück und mit der Funktion .sample() kann man eine beliebig große Zufallsstichprobe aus den Daten ziehen. Diese spuckt standardmäßig jedoch nur eine Zeile aus. Jetzt schauen wir uns die Dimensionen des Datensatzes an.
df.shape
(52861, 91)
Der Datensatz besteht also aus 52.861 Zeilen (ohne Kopfzeile) und 91 Spalten (ohne Index). Gucken wir uns dazu noch die Datentypen der einzelnen Spalten an.
df.dtypes


Auf den ersten Blick sieht der Datensatz in Ordnung aus. Mit „in Ordnung“ meine ich nicht, dass man sofort mit der explorativen Datenanalyse (EDA) beginnen kann. Viel mehr ist gemeint, dass es zumindest so aussieht, als würde jede Zeile eine Wohnung repräsentieren und der Inhalt der Spalten zu deren Namen passen. Wenn zum Beispiel in den ersten 5 Zeilen der Spalte „obj_baseRent“ (Kaltmiete) nur True und False stehen würden, dann hätten wir ein Problem.
True und False in Zahlen umwandeln
A propos True und False: Einige Spalten stellen Wahrheitswerte dar. Sie sagen zum Beispiel aus, ob eine Wohnung einen Balkon oder einen Keller hat. Im Quellcode von Immobilienscout24 werden diese Werte jedoch mit „y“ und „n“ abgespeichert, was für Python einfach nur beliebige Strings sind. Das sehen wir auch daran, dass die Datentypen dieser Felder nicht „boolean“, sondern „object“ sind. Damit Python mit den Einträgen arbeiten kann, muss in den Zellen True oder False stehen. Wir inspizieren erst mal alle Felder mit nur zwei Ausprägungen.
for i in df:
x=df[i].value_counts()
if len(x)==2:
print(x)
print("="*50)
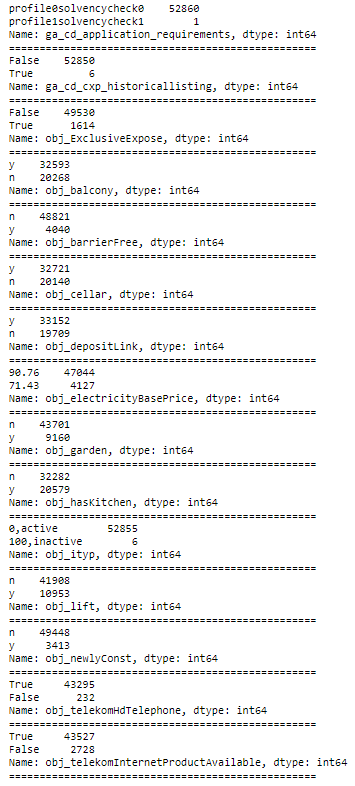
Der Code oben iteriert über die Spalten des Dataframes und prüft jedes Mal, ob die Spalte nur aus zwei Ausprägungen besteht. Meistens sind die Einträge dieser Spalten Wahrheitswerte. Wie der Output zeigt, ist das auch tatsächlich der Fall. Was uns besonders interessiert, sind die Spalten mit „y“ und „n“ („yes“ und „no“). Wir wissen, was damit gemeint ist, Python nicht. Deshalb müssen die Einträge in Wahrheitswerte umgewandelt werden.
df.obj_balcony = df.obj_balcony.replace("n",False).replace("y",True)
df.obj_barrierFree = df.obj_barrierFree.replace("n",False).replace("y",True)
df.obj_depositLink = df.obj_depositLink.replace("n",False).replace("y",True)
df.obj_cellar = df.obj_cellar.replace("n",False).replace("y",True)
df.obj_garden = df.obj_garden.replace("n",False).replace("y",True)
df.obj_hasKitchen = df.obj_hasKitchen.replace("n",False).replace("y",True)
df.obj_lift = df.obj_lift.replace("n",False).replace("y",True)
df.obj_newlyConst = df.obj_newlyConst.replace("n",False).replace("y",True)
Wenn wir jetzt denselben Befehl wie oben noch mal ausführen, sehen wir, dass die Werte in den Spalten umgewandelt wurden.
for i in df:
x=df[i].value_counts()
if len(x)==2:
print(x)
print("="*50)
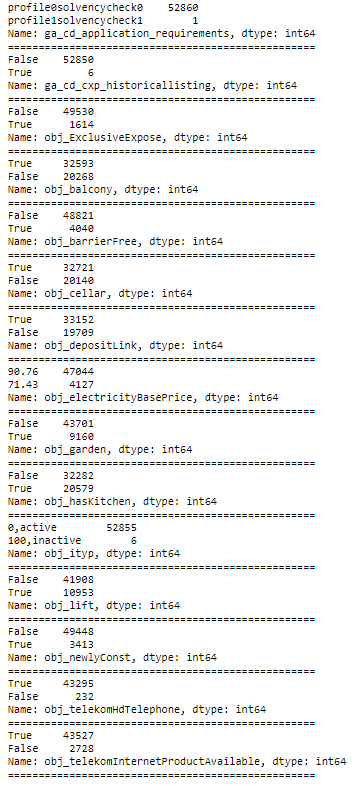
Damit kann Python arbeiten. True und False sind in Python fast dasselbe wie 1 und 0. Wenn man einen Array von True- und False-Werten hat, dann entspricht die Summe aller Werte im Array der Anzahl der True-Werte. Analog dazu ist der Durchschnitt eines solchen Arrays die Anzahl der True-Werte dividiert durch die Anzahl aller Werte.
Duplikate prüfen
Jetzt überprüfen wir anhand des Merkmals „URL“, ob sich jede Wohnung auch nur einmal in den Daten befindet. Jede Wohnung hat genau eine URL und jede URL verweist auf genau eine Wohnung.
df.URL.value_counts()

Die Funktion .value_counts() gibt einen mit einem Index versehenen Array zurück. Der Index ist hier die URL und der Array besteht aus absoluten Häufigkeiten. Wir sehen also, wie oft die betreffende URL im Datensatz zu finden ist. Da die Werte von der Funktion absteigend sortiert werden und der oberste Wert 1 ist, können wir davon ausgehen, dass der Datensatz keinerlei Duplikate enthält.
Strings, die Zahlen repräsentieren
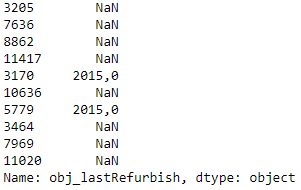
Außerdem ist es wichtig, dass alle numerischen Spalten auch als Zahlen erkannt werden (also als „float“ oder „int“). Wenn das noch nicht der Fall ist, müssen diese umgewandelt werden. Beim Untersuchen der Datentypen ist mir aufgefallen, dass ein paar Spalten als „object“ erkannt wurden, mit denen wir eigentlich Berechnungen durchführen wollen. Genauer gesagt sind es die Merkmale „Etage“, „Jahr der letzten Renovierung“ und „Baujahr“ – zumindest vorerst. Warum diese Spalten nicht als numerisch Werte eingelesen wurden, zeigt der folgende Output.
df.obj_floor.sample(10)

df.obj_lastRefurbish.sample(10)
df.obj_yearConstructed.sample(10)

Im Prinzip liegt überall dasselbe Problem vor. Und zwar erkennt Python ein Komma nicht als Dezimaltrenner, sondern nur einen Punkt. Man kann das Komma zwar schon beim Importieren als Dezimaltrenner definieren, jedoch würden dann möglicherweise andere Spalten, welche jetzt als Zahl erkannt werden, als Objekte importiert werden. NaN steht übrigens für „not a number“. In unserem Fall heißt das einfach, dass für die betreffende Wohnung kein Wert angegeben wurde. Dann wandeln wir jetzt die Kommata in Punkte um und formatieren die Spalten als „float“.
df.obj_lastRefurbish = df.obj_lastRefurbish.str.replace(",",".").astype(float)
print(df.obj_lastRefurbish.dtype)
df.obj_floor = df.obj_floor.str.replace(",",".").astype(float)
print(df.obj_floor.dtype)
df.obj_yearConstructed = df.obj_yearConstructed.str.replace(",",".").astype(float)
print(df.obj_yearConstructed.dtype)

Sieht schon mal gut aus. Gucken wir uns noch mal eine Stichprobe an.
df.obj_floor.sample(10)

Hat geklappt (man beachte die Dezimalpunkte). Die anderen beiden Spalten sehen genauso aus. Damit können wir nun rechnen.
Datumswerte
Oft sind auch Datumswerte Teil von Datensätzen. In unserem Fall ist es die Spalte „timestamp“, welche die Zeit angibt, zu der das Wohnungsangebot heruntergeladen wurde. Das ist mit einer Differenz von höchstens einer Minute (Schlafzeit des Scrapers) auch die Zeit, zu der das Angebot online gestellt wurde.
Mit der folgenden Funktion können wir die Spalte ganz einfach in ein Datumsformat bringen.
Vorher:
df.timestamp.dtype
dtype('O')
Der Datentyp ist „object“.
Umwandeln:
df.timestamp = pd.to_datetime(df.timestamp)
Nachher:
df.timestamp.dtype
dtype('<M8[ns]')
Grob gesagt bedeutet dieser Output, dass die Einträge der Spalte „timestamp“ jetzt im Datetime-Format vorliegen.
Fertig
So! Damit sind wir mit der grundlegenden Datensäuberung fertig und können im nächsten Teil der Artikelreihe mit der EDA beginnen.